
[운영체제/OS] 메모리 관리 - 디맨드 페이징과 페이지 부재(Page Fault) Issue
kindof
·2021. 6. 14. 20:47
💡 1. Remind
가상 메모리는 Virtual 또는 Logical Memory라고 부르는데, 이전에 메모리 관리를 공부하면서 사용해왔던 개념입니다.
멀티프로세싱 환경에서 각 프로세스는 자신의 가상 메모리 공간을 갖고 있고, 런타임에 물리적 메모리 공간에 올려서 사용하는 것이었죠.
가상 메모리 사용의 가장 핵심적인 목표는 프로그래머가 물리적 메모리 공간에 대해 신경쓰지 않고, 논리적 메모리에 대해서만 고민하게 하는 것입니다.
이를 위해 모든 가상 메모리는 통째로 물리적 메모리에 올려지는 것이 아니라, 공유 가능한 부분은 공유하고 / 실제 사용하는 영역만 물리 메모리에 올려집니다. 이를 통해 엄청나게 많고 커다란 프로세스들을 한정된 물리적 메모리 공간 안에서 돌아갈 수 있는 것이죠.
다시 말해, "RAM이 16GB라고 하면 32-bit architecture에서 각 PCB는 4GB이고 수 천개의 프로세스가 돌아가는데, 어떻게 이 주소들을 RAM에 올리는 것일까?"라는 물음에 대한 답이 "모든 가상 메모리를 물리적 메모리에 올리지 않고, 필요한 부분만 + 공유 가능하면 한 번만 올리는 것"이라는 것입니다.
그러면 이제 실제로 이 과정을 구현하는 방법 중 하나인 디맨드 페이징(demand Paging) 기법에 대해 알아보겠습니다.
2. 디맨드 페이징(Demand Paging)
디맨드 페이징(Demand Paging)은 이름 그대로 필요한 부분의 페이지 영역만 물리적 메모리에 할당하는 방법입니다.
예전 포스팅에서 Swapping에 대해 얘기한 적이 있는데, 여기서 Swapping의 개념은 아래와 같이 재정의됩니다.
- 기존 Swapping: 물리적 메모리에 존재하는 프로세스 자체를 HDD 등 Storage로 뺐다가 재배치했다가 하는 과정
- 새로운 Swapping: 물리적 메모리에 존재하는 프로세스의 "페이지" 일부를 뺐다가 재배치했다가 하는 과정
위와 같은 Swapping 개념의 변화를 통해 우리는 한 시점에서 빈번히 쓰이는 페이지만 물리적 메모리에 담아서 사용하게 됩니다.
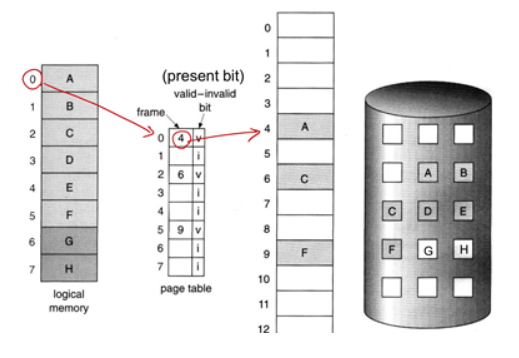
그림을 보면 맨 왼쪽의 프로세스가 가지는 여러 개의 페이지 중에서 실제로 물리적 메모리에 올라가 있는 것은 A, C, F밖에 없습니다.
프로세스가 돌아가는 동안 MMU는 실시간으로 페이지 테이블을 확인하고, 필요한 페이지가 물리적 메모리에 있는지를 확인합니다. 이 때 페이지 테이블의 Present bit이 1인지, 0인지 여부가 물리 메모리에 해당 페이지가 저장되어 있는지를 알려줍니다. 또한 페이지 테이블 엔트리에는 해당 페이지가 Swap-out될 때, Backing Storage의 어느 위치에 저장되는지에 대한 정보도 저장하고 있습니다.
한편, 만약 Present bit이 0이면 사용하려는 페이지가 물리적 메모리에 지금 없다는 뜻인데, 우리는 이 상황을 Page Fault라고 합니다.
3. Page fault Handling
Page Fault는 내가 가진 모든 페이지가 램(RAM)에 존재하는 게 아니기 때문에 필연적으로 일어날 수밖에 없습니다.
그렇다면 이런 상황을 어떻게 대처할까요? 우선 기본적인 Page fault handling 메커니즘을 아래 그림을 통해 이해해보겠습니다.

1) 프로세스는 자신이 사용하고자 하는 페이지가 page table에 존재하는지 확인한다.
2) 만약 physical memory에 사용하려는 page가 없으면, Page fault exception이 발생하고 커널모드로 전환된다.
3) OS는 page table entry의 정보 속에서 Backing storage의 어느 위치에 page가 존재하는지 확인한다.
4) 필요한 페이지를 physical memory에 load한다.
5) page table를 다시 업데이트 해준다.
6) 그리고 이제 원래 하려고 했던 instruction을 수행해준다.
그런데 이 때, 페이지 테이블을 읽고 Page fault로 인한 커널 모드 전환을 하는 데는 크게 시간이 안 걸리지만 backing store에서 페이지를 찾아오는 과정이 꽤 긴 시간이 소요됩니다.
그리고 무작정 물리 메모리의 크기를 엄청 키워서 Page fault를 안 일어나게 하는 것은 불가능하기 때문에 Page fault를 핸들링하는 데 드는 어느 정도의 시간은 필연적으로 소모될 수밖에 없죠.
그런데 문제는 약 2,500,000번 중에 한 번만 Page Fault가 발생해도 약 10%의 성능 저하가 발생해버린다는 겁니다. 근데 현실적으로 2,500,000번 중에 1번만 page fault가 뜨는게 가능할까요?
위 질문에 대한 답을 하기 위해서는 Locality라는 개념을 알아야 합니다. 실제로 우리가 사용하는 코드를 생각해보면 거의 대부분의 코드가 Loop, 사용한 코드의 재사용 등으로 이루어져 있습니다. 이를 Locality(지역성)이라고 하는데, Locality 덕분에 한 번 사용하려는 페이지를 페이지 테이블에 넣어놓으면 한동안 주구장창 사용하다가 코드 구역이 넘어가면 swap-out하는 것이죠.
즉, Locality 개념 덕분에 page fault는 우려하는 것만큼 빈번히 일어나지 않는 것입니다. 그럼에도 불구하고, Locality가 잘 지켜지지 않는 코드도 분명 있기 때문에 항상 page fault 성능 이슈를 해결할 수 있는 것은 아니죠.
그리고 위 과정을 잘 생각해보면 한 가지 문제점이 더 존재합니다.
애초에 지금 찾는 페이지가 backing store에 있다는 것은 물리 메모리가 꽉 차있어서 Swap-out 된 녀석이라는 뜻인데...😳
그러면 해당 페이지를 다시 불러와서 물리 메모리에 로드하려면, 어떤 페이지를 다시 Swap-out해야 할까요?
이에 대한 기준을 제시해주는 내용이 바로 페이지 교체 정책입니다. 이 내용에 대해서는 다음 포스팅에서 자세히 정리해보겠습니다.
'CS > OS' 카테고리의 다른 글
| [운영체제/OS] 프레임 할당(Frame allocation)과 Page fault 관련 기타 이슈들 (1) | 2021.06.14 |
|---|---|
| [운영체제/OS] 여러가지 페이지 교체 정책에 대해 (0) | 2021.06.14 |
| [운영체제/OS] 메모리 관리 - 세그멘테이션(Segmentation)과 페이징 기법 (0) | 2021.06.14 |
| [운영체제/OS] 메모리 관리 - 페이징(Paging) 기법 (0) | 2021.06.14 |
| [운영체제/OS] 메모리 관리 - 파티셔닝과 버디 시스템(Buddy system) (0) | 2021.06.14 |





