
[운영체제/OS] 메모리 관리 - 파티셔닝과 버디 시스템(Buddy system)
kindof
·2021. 6. 14. 20:44
이번 포스팅에서는 메모리 관리를 실전(?) 방법들에 대해서 공부하려고 합니다.
단, 지금부터 소개하는 방법들은 기본적으로 프로세스의 크기만큼 물리 메모리에 충분한 공간이 있음을 가정합니다. 이전 시간에 스와핑에 드는 Transfer time이 꽤 크다는 것을 이야기했었는데 지금은 이 부분을 고려하지 않겠다는 뜻입니다. 이전 포스팅을 아직 안 보신 분은 한 번 보고 오시면 이해가 더 편하실 것 같습니다.
[운영체제/OS] 메모리 관리(Memory Management) - 물리적, 논리적 주소 공간과 스와핑(Swapping)
💡 0. 들어가면서 이전 포스팅까지 CPU 스케줄링, 멀티프로세싱과 멀티쓰레딩, 그리고 동기화 및 데드락 이슈에 대해 공부했습니다. 메모리 관리(Memory Management)는 하나의 물리적인(Physical) 메모리
studyandwrite.tistory.com
그리고 '물리 주소 공간에 공간이 부족할 때는 어떻게 할 것인가?'에 대한 이슈는 나중에 페이지 교체 정책에 대해서 공부 할 때 다루겠습니다.
📖 1. Fixed Partitioning
이 방법은 메인 메모리를 여러 파티션(Partition)으로 나누고, 파티션의 크기보다 작은 프로세스를 할당할 수 있도록 하는 정책입니다. 단, 여기서 파티션의 사이즈는 모두 똑같을 수도 있고 조금씩 다를 수도 있습니다.
정말 간단한 메모리 할당 방법인만큼 이 방법에서는 크게 두 가지의 문제가 생길 수 있습니다.
- 하나의 프로세스가 하나의 파티션을 모두 차지하기 때문에, Internal fragmentation이 발생할 수 있다는 점입니다. 설령 파티션의 크기를 다르게 쪼갠다고 하더라도, Internal fragmentation이 적어질 수는 있지만 이 문제를 완벽히 해결하기는 어렵습니다.
- 하나의 프로그램이 파티션의 크기보다 클 경우, 이 프로그램은 애초에 메모리에 할당될 수가 없습니다. 따라서 프로그래머는 Overlay 기법을 사용해야만 하는 상황에 놓입니다.
✅ *Overlay란?
whenever a process is running it will not use the complete program at the same time, it will use only some part of it.
Then overlays concept says that whatever part you required, you load it an once the part is done, then you just unload it, means just pull it back and get the new part you required and run it.
Overlay는 메인 메모리의 공간이 부족할 때 큰 프로세스를 돌리는 방법입니다.
만약 어떤 거대한 프로그램 P가 함수 A, B를 호출하고 / 함수 B는 또다시 C, D함수를 호출하는 상황을 생각해보겠습니다. 이 모든 프로세스를 한 번에 메모리에 올릴 수 없을 때는 Call graph에 따라 적절한 순서(의존성 있는)로 메모리에 로딩합니다.

그런데 이러한 Overlay Map은 개발자가 직접 설계해야 하고, 메모리에 대한 요구 사항 등을 복잡하게 고려해야 합니다. 또한 오버레이된 모듈들은 서로 완벽히 독립적이어야 하고, 모든 케이스에 대해 항상 가능하지는 않습니다.
다시 본론으로 돌아와서, Fixed Partitioning을 통해 메모리를 관리하는 구체적인 알고리즘에는 아래와 같은 방법이 있습니다.
1) Use of multiple queues
- 각각의 프로세스를 자신보다는 크지만 가장 작은 파티션에 넣기 위해 각각의 파티션에 대한 큐(queue)를 만들어두는 방식입니다.
- internal fragmentation을 감소시킬 수는 있지만, 특정 partition에만 프로세스가 몰리는 현상이 발생할 수도 있습니다.
2) Use of a single queue
- 하나의 큐에 프로세스를 저장하고, 그 프로세스를 수용할 수 있는 가장 작은 파티션에 할당하는 방법입니다.
- 이 방법에서는 큰 공간에도 작은 프로세스를 할당할 가능성이 생겨서 internal fragmentation이 생길 수는 있지만, 프로세스를 무작정 대기큐에서 기다리게 하지 않고 파티션에 할당함으로써 concurrent하게 작업을 돌릴 수는 있는 장점이 있습니다.
📒 2. Dynamic Partitioning
Dynamic Partitiong에서는 각 파티션의 길이가 유동적입니다. 각 프로세스는 딱 자신의 크기만큼 파티션 사이즈를 할당받기 때문에 internal fragmentation이 없습니다.
Dynamic Partitioning의 구체적인 알고리즘에는 아래와 같이 여러 방법이 있는데요.
1) Best-fit: Process를 담을 수 있는 가장 작은 크기의 hole을 선택하기
2) First-fit: 처음 시작점부터 스캔하면서 자신을 담을 수 있는 hole 선택하기
3) Next-fit: 마지막으로 할당된 hole부터 스캔하면서 자신을 담을 수 있는 hole 선택하기
4) Worst-fit: 가장 큰 사이즈의 hole을 선택하게 되면, 남은 hole의 크기도 클 것을 예상해서 다른 process가 또 사용할 수 있게 하는 방법
Dynamic partitioning에서 실제 메모리가 어떤 식으로 할당되는지 아래 그림을 통해 보겠습니다.
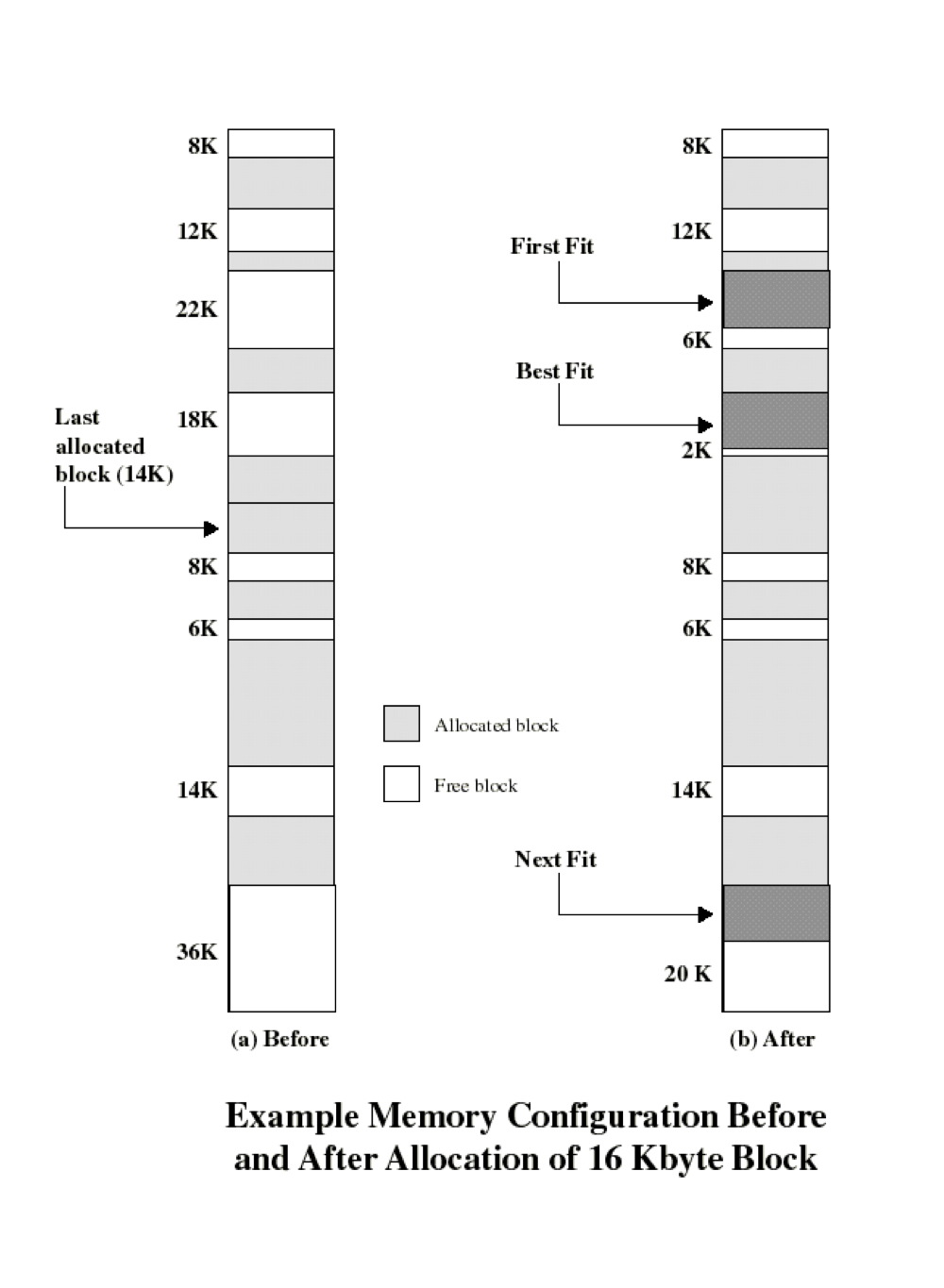
위 그림에서 메모리의 상단이 메모리의 하위 주소를 나타냅니다. 16K 크기의 새로운 파티션을 할당할 때, First fit 같은 경우 하위 메모리부터 탐색을 시작하여 자신보다 공간이 큰 곳을 발견하면 그 공간에 바로 할당하고 있으며, Best fit 방법의 경우에는 빈 공간들 중에서 자신보다는 크고, 가장 작은 공간을 할당받게 됩니다.
Next-fit은 왼쪽 그림에서 이전에 14K 크기의 파티션이 할당된 위치부터 시작하여 그 다음 공간들 중에서 자신이 들어갈 수 있는 공간을 찾습니다.
참고로 Worst-fit은 가장 큰 공간에 메모리를 할당하는 방법인데, 이렇게 하면 그만큼 더 커다란 hole이 생기기 때문에 다른 자원이 이를 활용할 가능성을 높여줍니다.
하지만 위의 여러 방법들을 아무리 잘 써도 Dynamic partitioning은 프로세스를 할당하다보면 연속적인 메인 메모리 공간에서 이미 할당된 공간 사이에 비어 있는 "hole"이 발생하고 이것이 External fragmentation이라는 비효율성을 낳게 될 수밖에 없는 구조입니다.
한편 아래 그림을 보면 Compaction이라는 개념의 모티브를 알 수 있는데요.

위 그림에서 (f)에서 (g)로 갈 때 P1이 swapped out되고, P2가 배치됩니다. 결국 (h) 상황에 이르렀을 때에는 두 개의 96K 메모리와 64K 메모리가 놀게 되죠. 굉장한 메모리 낭비가 아닐까요? 이를 해결하기 위한 개념이 바로 Compaction입니다.
Compation이란 external fragmentation 문제를 해결하기 위해 할당된 프로그램들을 차곡차곡 밀고 옮겨서(relocation) 공간을 효율적으로 확보하는 것을 말합니다.
이렇게 메모리 공간을 동적으로 재조정하는 것은 Execution time에 일어나기 때문에 I/O Operation 같은 작업 중인 프로세스는 작업이 끝나고 메모리 주소를 옮겨줘야 합니다.

💻 3. 버디 시스템(Buddy System)
Buddy System은 Fixed, Dynamic Partitioning 기법의 fragmentation 발생 이슈를 보완하기 위한 방법입니다. 이 방법은 실제로 Linux OS에서도 사용하는 것으로, 꽤 중요한 방법이기도 합니다. 절차는 크게 어렵지 않게 이해할 수 있습니다.
1) 메인 메모리는 항상 2^N size로 할당한다.
2) 사용할 수 있는 가장 큰 메모리부터 시작해서 Binary로 절반씩 쪼개나가면서 아래 조건을 만족시키는 공간을 찾는다.
3) 만약 프로세스 메모리 크기가 K라고 하면, 2^(U-1) < K <= 2^U 를 만족시키는 U를 찾고, 2^U 만큼의 공간에 프로세스를 할당한다. 예를 들어, 프로세스 크기가 1000B이면, 512B < 1000B < 1024B이기 때문에 1024B 사이즈의 메모리에 할당하는 것이다.
4) 프로세스가 종료되고, 만약 같은 Parent를 갖는 Buddy 공간이 비어있다면 Merge한다.
위 과정을 조금 더 디테일하게 들여다보면, 메모리를 할당할 때는 가장 하위 메모리부터 탐색을 해가면서, 메모리를 할당할 수 있는 가장 작은 크기의 Block을 선택해서 쪼개든지 할당하든지 해야 합니다. 무슨 말인지 아래 그림을 통해 이해해보겠습니다.
|- - - -|- - - -|- - - -|- - X X|
<----------><----><--><-->
위 그림에서 'X' 표시는 이미 메모리가 할당된 상태를 의미합니다. 그렇다면 위의 메모리 공간은 버디 시스템에 의해 화살표와 같이 쪼개진 상태겠죠. 따라서, 만약 현재 상태에서 1칸짜리 메모리를 할당하려고 한다면, 가장 하위 주소부터 탐색하여 XX 바로 이전의 두 칸짜리 메모리를 쪼개서 사용해야 한다는 뜻입니다. 즉, 한 칸짜리 메모리를 할당하고 나면 다음과 같은 상태가 됩니다.
|- - - -|- - - -|- - - -|X - X X|
<----------><----><-><-><-->
또한, Merge 단계에서는 자신의 블록 사이즈가 2^N이었을 때 자신의 블록 주소의 N번째 비트를 ^ 연산한 값이 buddy의 블록 주소가 됩니다. 따라서, 아래와 같은 코드로 buddy의 주소를 찾을 수 있고, buddy가 자신과 같은 크기의 블록이며 물리 메모리에 할당되지 않은 상태라면 merge하게 됩니다.
int n = ceil(log(size) / log(2)); // 자신의 블록 사이즈
int buddyAddr = index ^ (1 << n); // 자신의 주소 bit 중에서 n번째 bit만 역으로 만들어주면, buddy의 주소가 된다.위의 설명으로만으로는 이해하기가 어려울 수 있어서 아래 그림을 통해 버디 시스템의 작동 순서를 다시 살펴보겠습니다.
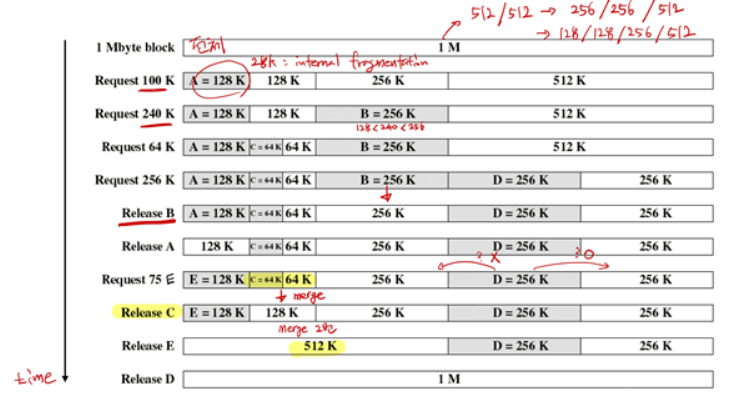
맨 처음에는 1M만큼의 전체 메모리가 존재하고, 100K의 프로세스가 요청될 때 메모리를 쪼개가면서 128K의 공간을 할당합니다. 이런 과정을 반복하다가 어떤 Process가 Release되면 자신의 Buddy(같은 부모로부터 Split된 녀석)을 찾고, Buddy가 비어있다면 Merge합니다.
버디 시스템을 쓰게 될 때 장단점은 무엇일까요? 버디 시스템은 Dynamic Partitioning에 비해 External Fragmentation이 적으며 하위 메모리부터 공간을 사용하기 때문에 자동적으로 Compaction에 대한 오버헤드가 적습니다. 하지만, 2^n 크기의 메모리를 무조건 할당해야하기 때문에 Internal Fragmentation이 필연적으로 존재할 수밖에 없습니다.
🚗 4. 나가면서
이번 포스팅에서는 Fixed, Dynamic Partitioning 기법과 버디 시스템 기반의 메모리 관리 기법에 대해 공부했습니다. 그리고 이러한 메모리 관리 기법에서 발생하는 Fragmentation, Overlay, Compaction 등의 개념에 대해 다뤘습니다.
위에서 정리한 것처럼, 어떤 메모리 관리 기법을 사용해도 완벽히 메모리를 관리하기는 어렵습니다. 다만, 조금이라도 메모리 낭비를 줄이고, 어떻게 하면 오버헤드를 적게 가지고 가면서 메모리를 관리할 수 있을까를 고민해야 하는 것이죠.
다음 글에서는 매우 중요한 메모리 관리 기법 중 하나인 페이징(paging)기법에 대해 알아보겠습니다.
감사합니다.
'CS > OS' 카테고리의 다른 글
| [운영체제/OS] 메모리 관리 - 세그멘테이션(Segmentation)과 페이징 기법 (0) | 2021.06.14 |
|---|---|
| [운영체제/OS] 메모리 관리 - 페이징(Paging) 기법 (0) | 2021.06.14 |
| [운영체제/OS] 메모리 관리 - 물리적, 논리적 주소 공간과 스와핑(Swapping) (0) | 2021.06.14 |
| [운영체제/OS] 데드락(Deadlock) 핸들링하기 (0) | 2021.06.14 |
| [운영체제/OS] 데드락(Deadlock)의 개념과 발생조건 (0) | 2021.06.14 |





