
[운영체제/OS] 데드락(Deadlock) 핸들링하기
kindof
·2021. 6. 14. 20:40
0. 들어가면서
지난 시간에 데드락이란 무엇이며, 어떤 상황에서 발생할 수 있는지에 대한 필요조건에 대해 공부했습니다. 데드락이 발생하기 위한 필요조건 네 가지는 다음과 같았는데요.
1. 상호배제(Mutual Exclusion): Non-sharable한 resource가 존재해야 한다.
2. 점유대기(Hold and Wait): 프로세스는 Resource를 점유하고 있는 동시에 다른 프로세스가 들고 있는 Resource를 Wait하고 있다.
3. 비선점(No preemption): Resource는 자신을 점유하고있는 프로세스에 의해서만 release될 수 있다.
4. 순환대기(Circular wait): 2번 내용을 포함하고 있는데, 그래프에 Cycle이 있어야 한다는 것이다.이 조건들을 설명하면서, 위 네 가지 조건이 모두 동시에 존재해야만 데드락이 발생할 수 있기 때문에 역으로 데드락을 방지하는 방법은 위 조건 중 하나를 제거해주는 것이라고 말씀드렸습니다.
그러면 본격적으로 데드락을 핸들링하는 방법에 대해 살펴볼텐데요.
데드락을 핸들링하는 방법은 크게 Deadlock Prevention와 Deadlock Avoidance 두 갈래가 있습니다. Deadlock Prevention은 "데드락이 절대 발생하지 않도록 하겠다"는 것이고, Deadlock Avoidance는 "데드락을 방지해보겠다"라는 의미의 차이가 있죠.
하나하나 살펴보겠습니다.
1. Deadlock Prevention
데드락이 절대 발생하지 않도록 만드는 아이디어는 간단합니다.
바로 데드락 발생의 필요조건 네 가지(상호배제, 점유대기, 비선점, 순환대기) 중 하나를 깨버리는건데요. 각각의 조건을 어떻게 깰 수 있을까요?
1) 상호배제(Mutual Exclusion)는 Non-sharable한 자원이 존재한다는 개념입니다. 즉, 자원의 수보다 자원을 할당받으려고 하는 프로세스의 수가 많아야 하며 Non-sharable한 자원이 분명 존재해야 한다는 것이죠. 그렇다면 프로세스 수보다 자원의 수를 더 많게 하면 실질적으로는 상호 배제가 깨집니다. 하지만 어떤 자원이 여러 프로세스에서 공유 가능한가, 불가능한가에 대한 문제는 사용자 입장이 아닌 시스템과 자원의 입장에서 생각해야되기 때문에 우리가 쉽게 컨트롤할 수 있는 영역이 아니죠. 뿐만 아니라, 애초에 Non-sharable하다는 것은 자원 자체의 내재적인(Intrinsic) 특징이기 때문에 우리가 컨트롤하기 어렵습니다. 즉, 상호배제 조건을 깨는 것은 쉽지 않다는 것이죠.
2) 점유대기(hold and Wait)를 깨버리기 위해서는 프로세스가 자원을 요청할 때, 다른 어떤 자원도 들고 있지 않도록 만들어야 합니다. 다시 말해서, 딱 필요한 시점에 실행 가능한 자원이 있으면 그 때 자원을 전부 할당받아서 다른 자원을 기다리는 상황을 만들지 않는 것입니다. 그리고 만약 충분한 자원이 없을 때는 자원을 점유하고 있지 않음으로써 다른 프로세스가 필요 시 자원을 할당받을 수 있도록 만드는겁니다.
3) 비선점(No preemption)을 깨기 위해서는 프로세스가 다른 자원을 wait하고는 있지만 할당받지 못하는 상황에서 점유하고 있는 자원을 Release하고 롤백(Rollback)하면 됩니다. 딱 필요한만큼의 자원이 사용가능할 때만 이전에 Release했던 자원과 요청 가능한 자원을 받아서 실행하도록 합니다. 이러한 방법은 프로세스가 쉽게 저장되고 다시 복구하기 편한 것들(CPU registor, memory ..)에 가능합니다.
4) 순환대기(Circular Wait)를 깨는 것은 위의 3가지 내용과는 다른 특징이 있습니다. 바로 우리 힘으로 데드락을 발생시키지 않도록 할 수 있다는 점인데요. 위의 3가지 데드락 발생 상황을 깨는 것은 사실 자원의 특징을 바꿔야 하는 부분이 많기 때문에 인위적으로 조정하는 것이 어려울 수 있습니다. 하지만 순환 대기(Circular wait)을 깨는 것은 어느적으로 인위적인 조정이 가능하죠. 예를 들어 자원에 순서를 부여하여 프로세스의 순서의 증가 방향으로만 할당되도록 하는, 즉, 순서를 만들어서 Circular한 상황이 안 생기도록 하는 방법이 있겠죠.
2. Deadlock Avoidance
Deadlock Avoidance는 데드락이 발생하지 않도록 최대한 예방해보자는 개념입니다. 이 방법의 핵심 아이디어는 어떤 프로세스가 어떤 자원을 요청하는지 계속 관찰하면서 자원을 할당했을 때 데드락이 발생할 것 같으면 자원을 할당해주지 않는 것입니다.
즉, 이 방식은 프로그램의 런타임에 계속해서 프로세스와 자원을 체크해서 안전한 상태(Safe state)를 유지하려는 방식이죠. 그런데 잠깐 안전 상태(Safe state)란 무엇일까요?
A state is safe if the system can allocate resources to each thread (up to its maximum) in some order and still avoid a deadlock. More formally, a system is in a safe state only if there exists a safe sequence.
즉, 여러 쓰레드를 돌리는 상황에서 각 쓰레드에게 자원을 할당할 순서를 부여하는 것입니다. 어떻게 보면 일종의 스케줄링이라고 볼 수 있는데요. 적절한 자원 할당 스케줄링을 통해 Circular-wait Condition이 발생하지 않도록 하여 데드락을 예방하는 것이죠.
한편 이 방식에서 프로세스와 자원의 상황을 런타임에 계속 확인하기 위해서는 Priori information이 합니다. Priori information이란 모든 프로세스가 OS에게 "나는 얼만큼의 자원이 필요해"라는 정보를 미리 알려줘야 한다는 것입니다.
이제 위와 같은 데드락 방지를 위한 방법으로 사용되는 Banker's Algorithm에 대해 살펴보려고 하는데요.
Banker's Algorithm은 "자원을 할당했을 때 Safe State가 될까?"라는 아이디어에 기반하여 시뮬레이션을 하는 알고리즘입니다. 아래서 살펴볼 내용들이 모두 Banker's Algorithm이라고 이해할 수 있는데요.
우선 Banker's Algorithm에 사용되는 몇 가지 자료구조와 Safe state를 정의하는 방식에 대해 짚어보겠습니다.
1) Banker's Algorithm Variables
1. Available: 길이가 m인 벡터로, 만약 available[j] = k라는 것은 j타입의 Resource가 현재 k개 사용 가능하다는 뜻이다.
2. Max: n*m matrix로, Max[i,j] = k라는 것은 프로세스 i가 j타입의 Resource를 k개 요청할 수 있다는 것이다.
3. Allocation: n*m matrix로, Allocation[i,j] = k라는 것은 프로세스 i가 j타입의 Resource를 현재 k개 할당받았다는 것이다.
4. Need: n*m matrix로, Need[i,j] = k라는 것은 프로세스 i가 현재 j타입의 Resource를 k개 더 필요로 한다는 것이다.
- 위 내용을 종합해보면, Need[i,j] = Max[i,j] - Allocation[i,j] 라는 것을 알 수 있다.
2) Safety Algorithm
Safety algorithm은 위에서 공부한 Safe state를 판별할 수 있는 알고리즘입니다. 내용은 어렵지 않은데요.

각 프로세스들의 종료 상태를 False로 초기화하고, Work는 현재 사용 가능한 자원들의 정보로 초기화합니다.
그리고 반복문을 수행하면서 아직 종료되지 않은 프로세스 중, 필요한 자원이 할당 가능한 자원보다 적은 녀석을 골라 자원을 할당해주고 이 프로세스를 종료시키는 동시에 가지고 있던 모든 자원을 반납시킵니다. 그러면 사용 가능한 자원(Work)의 양은 늘어나서 이를 바탕으로 또 다른 프로세스에게 자원을 할당할 수 있겠죠?
이렇게 반복적인 과정을 수행하여 모든 프로세스가 종료 상태가 되면, Safe state 상태를 만족하게 된다는 것입니다.
3) Resource-Request Algorithm
다음으로 우리는 어떤 요청이 안전하게 받아들여질 수 있는지에 대한 알고리즘을 보려고 합니다.
Request는 벡터로써, Request_i[j] = k라는 것은 프로세스 i가 j타입의 Resource를 k개 요청한다는 의미이다.이를 바탕으로 한 알고리즘은 아래와 같습니다.

이 알고리즘 역시 어렵지 않습니다. 만약 필요한 자원(Request)이 사용 가능한 자원(Available)보다 적으면 Available에서 Request만큼 빼서 자원을 할당하고, 할당받은 자원(Allocation)은 기존의 값에 할당받은 Request만큼을 더합니다. 그리고 앞으로 더 필요한 자원의 양(Need) 역시 Request만큼 빼주면 됩니다.
만약 위에서 실행한 알고리즘의 결과로 자원 할당이 Safe한 상태라면 자원을 정상적으로 할당하고, Unsafe하다면 할당되지 않으면 됩니다.
예를 들어보겠습니다.
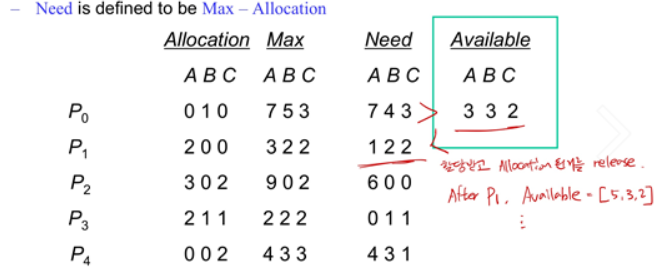
위의 예시에서는 P1의 Need값이 Available한 Resource보다 작기 때문에 P1이 실행될 수 있고, 실행이 완료되면 사용한 자원을 release하기 때문에 Available한 Resource가 증가합니다.
그렇게 되면 다음에 P3의 Need값보다 Available값이 커지게 되고 P3를 실행할 수 있습니다.
이 과정을 반복하게 되면 <P1, P3, P4, P2, P0>의 순서로 safety criteria를 만족시킬 수 있죠.
그런데 만약 P1이 (1, 0, 2)만큼 추가적인 Request가 있다면 어떨까요? 그렇다면 현재 Allocation 값을 [3, 0, 2]로 증가시키고 Available한 양을 [1, 0, 2]만큼 감소시켜줍니다. 그 후에 다시 Need 값과 Available 값을 비교하면서 풀어보면 <P1, P3, P4, P0, P2>의 순서대로 실행했을 때 Safety criteria를 만족시킬 수 있습니다.
3. Deadlock Detection and Recovery
사실 위에서 설명한 Deadlock Prevention과 Avoidance는 오버헤드도 크고 priori information을 OS에게 제공하는게 현실적으로 쉽지 않다는 제약조건이 있습니다. OS가 모든 프로세스가 어떤 자원을 언제 얼만큼 필요로 할 지 다 알기는 어렵겠죠?
그래서 아래에 설명할 내용은 조금 더 현실적인 내용들입니다.
1) 데드락 감지(Detection)
이 방법은 시스템이 그냥 돌아가게 둔 다음에 데드락이 발생하면 그걸 발견하고 해결하는 방식입니다. Priori information도 필요없고 그냥 되는지 안되는지 일단 해보는 것이죠.
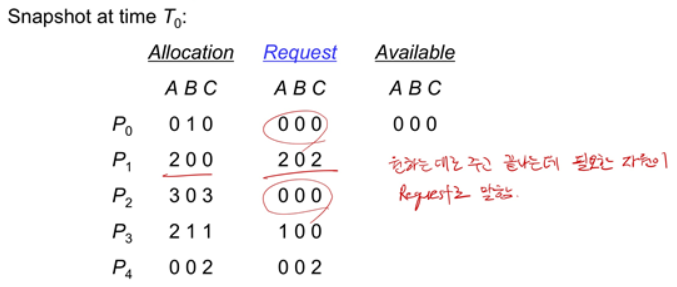
위 예시를 보면 Request는 현재 Allocation에서 더 필요한 Resource를 의미합니다. Request값이 Available값보다 작은 Process를 먼저 실행하고 실행이 끝나면 자원을 release하는 방식으로 Safe criteria를 만족시킬 수 있는지 확인해봅니다.
그러면 <P0, P2, P3, P1, P4> 순서대로 했을 때 가능하다는 것을 알 수 있죠.
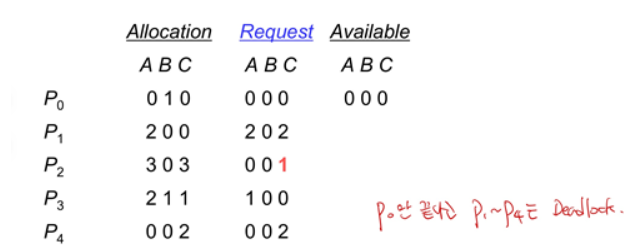
하지만 위의 상황처럼 P2가 Type C 자원을 하나 더 요청하게 되면 어떨까요?
지금 당장 실행 가능한 프로세스는 P0밖에 없는데 P0가 끝나고 자원을 release해도 다른 프로세스의 Request값이 모두 Available보다 크게 되어 Deadlock이 발생합니다.
2) 데드락 회복(Recovery)
데드락이 발생했으면 이제 Recovery를 해야겠죠. Recovery를 하는 방법은 간단합니다. Process를 죽이거나 Resource를 Preemptive하게 쓰거나.
하지만 모든 프로세스를 죽일 것인가? 아니면 어떤 프로세스를 어떤 기준으로 죽일 것인가?에 대한 물음에 쉽게 답변하기는 어렵습니다.
Resource를 Preemptive하게 쓰는 것도 어떤 자원을 그렇게 사용할 것인가, 어떤 프로세스의 자원을 뺐어올 것인가, Rollback을 하게 되면 어떻게 상태를 저장하고 Recover할 것인가? 계속 같은 프로세스의 자원을 preemptive하게 뺐어버리면 startvation 문제는 생기지 않는가? 등 여러가지 물음이 남아있죠.
그래서 교수님께서는 말씀하셨습니다. "데드락이 발생하면 컴퓨터를 꺼라" 데드락이 실제로 많은 상황에서 발생하는 일반적인 케이스도 아니며, 데드락을 해결하기 위해서 들이는 노력이 상당히 복잡하고 크기 때문이라고 합니다. 또한, 일반적인 용도로 사용되는 OS에서는 데드락 문제를 크게 신경쓰지 않는다고 합니다.
4. 나가면서
지금까지 데드락의 개념과 발생 시점, 그리고 이를 어떻게 해결할 것인가 등에 대한 이슈를 살펴보았는데요.
Deadlock Prevention을 통해 네 가지 데드락 발생 조건을 깨는 것, Deadlock Avoidance(Banker's Algorithm)으로 Safe State를 판별하여 적절한 스케줄링을 하는 것에 대해 배웠습니다.
하지만 위 방식은 Priori Information의 부재에 따른 한계점이 있어서 단순히 데드락을 Detection하고, Recover하는 이야기까지 해봤습니다.
이상으로 데드락에 대한 포스팅을 마치겠습니다.
감사합니다.
'CS > OS' 카테고리의 다른 글
| [운영체제/OS] 메모리 관리 - 파티셔닝과 버디 시스템(Buddy system) (0) | 2021.06.14 |
|---|---|
| [운영체제/OS] 메모리 관리 - 물리적, 논리적 주소 공간과 스와핑(Swapping) (0) | 2021.06.14 |
| [운영체제/OS] 데드락(Deadlock)의 개념과 발생조건 (0) | 2021.06.14 |
| [운영체제/OS] 동기화 이슈 처리하기 - (1) (0) | 2021.06.14 |
| [운영체제/OS] 동기화 이슈의 원인과 임계 구역(Critical Section)의 개념 (0) | 2021.06.14 |






