
[Multicore] 쓰레드의 Workload 관리와 Thread Pool에 대해
kindof
·2022. 3. 17. 00:21
1. 쓰레드의 Workload 밸런스
8개의 쓰레드를 가지고 천 만개의 원소를 가진 배열의 각 원소에 대해 특정한 연산(더하기나 빼기 등)을 하는 작업을 한다고 해보겠습니다.
그러면 우리는 각 쓰레드에 10,000,000 / 8 = 1,250,000 개의 원소에 대한 연산을 할당하고, 쓰레드가 작업을 마치면 결과를 모아서 다음 과정을 이어나갈 수 있습니다.
하지만 실제 멀티쓰레드 환경은 언제나 위와 같이 각 쓰레드가 동일하거나 비슷한 수준의 작업량을 할당받는 보장이 없습니다. 어떤 쓰레드는 다른 쓰레드보다 훨씬 더 많은 작업을 처리해야 할 수 있고, 또 다른 쓰레드는 정말 적은 양의 작업을 마치고 다른 쓰레드들이 끝나길 기다려야 할 수 있죠.

위 그림은 시간에 따른 4개 쓰레드의 작업 진행 상황입니다. 전체 시간의 절반의 시간은 P1, P2, P3, P4 쓰레드가 모두 자신의 작업을 하고 있지만, 나머지 절반 시간동안에는 P4 쓰레드만 자신의 작업을 이어나가고 있습니다.
즉, 우리는 병렬 프로그래밍을 한다고 했지만 정작 50%의 시간만 멀티쓰레드 환경에서 작업을 하고 있고 나머지 절반의 시간에는 하나의 쓰레드만 순차적인 작업을 하고 있는 것이죠.
이는 결국 전체 작업의 20%를 수행하기 위해 전체 수행 시간의 절반 가까이를 보내야 한다는 것인데요. 여러 쓰레드가 각자 처리해야 하는 작업량의 불균형이 결국에는 전체적인 병렬 프로그래밍의 성능 저하를 야기한다는 것입니다.
이 부분이 오늘 포스팅에서 다룰 쓰레드의 작업량(Workload) 관리와 쓰레드 풀에 대한 문제 제기이자 배경입니다.
어떻게 하면 여러 쓰레드들에 대해 작업량의 균형을 맞추고 효율적인 병렬 프로그래밍을 할 수 있을까요?
2. 정적 할당(Static Assignment)
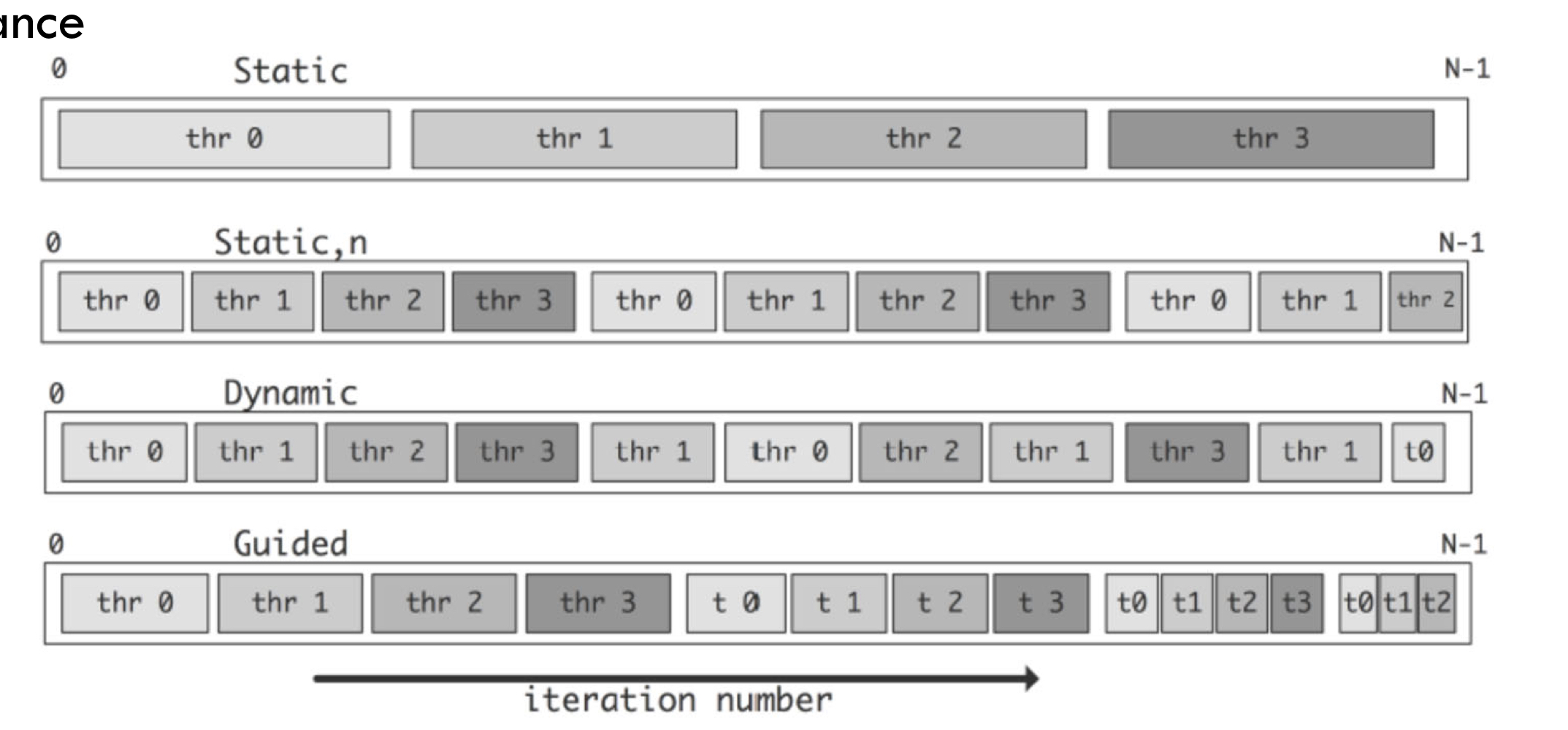
정적 할당은 각 쓰레드에 대해 일정한 작업량을 고정적으로 분배하는 방식입니다.
예를 들어, 아래와 같은 matrix A에 대해 모든 원소의 합을 구해야 한다면 각 쓰레드에 대해 똑같은 개수의 원소만큼을 할당하는 방식이죠.
정적 할당은 간단하고 쓰레드에 작업을 할당하는 데 오버헤드도 거의 들지 않습니다. 그리고 각 쓰레드가 처리해야 하는 작업량이 예측 가능(predictable)하다는 장점도 있죠.
그러나, 정적 할당의 가장 큰 약점은 전체 작업의 크기가 어느 정도인지 혹은 각 작업이 어느 정도의 시간이 걸릴 것인지 알 수 없는 상황에서는 사용하기 어렵다는 것입니다.
그래서 이제 아래의 Dynamic Assignment에 대해 알아보겠습니다.
3. 동적 할당(Dynamic Assignment)
위에서 말한 것처럼, 동적 할당(Dynamic Assignment)은 전체 작업량이나 각 작업의 크기가 불분명할 때 쓰레드에게 작업을 할당하는 방법입니다.
예를 들어, N개의 원소를 갖는 배열이 있고 각 원소에 대해 임의의 작업을 해야 한다고 해보겠습니다. 어떤 원소를 가지고는 긴 호흡의 연산이 이루어질 수 있고, 어떤 원소는 단순히 더하기만 할 수도 있습니다.
이런 상황에서는 아래와 같이 동적으로 작업을 할당할 수 있습니다.
#include <iostream>
#include <thread>
#include <vector>
void worker(int* input, int start, int size, int* output){
while(i < N){
global.lock();
i = counter++;
global.unlock();
do_something_on(input[i]);
}
}쉽게 생각하면 해야 하는 작업을 쌓아두고, 각 쓰레드가 찾아와서 하나씩 일거리를 찾아가는 방식이죠. 이렇게 하면 각 쓰레드에 대한 작업량의 편차는 아무리 커도 임의의 원소 K에 대한 작업량 정도를 초과하지 않죠.
다만, 위와 같은 방식의 문제점은 counter가 1씩 증가하기 때문에 N개의 원소를 처리하기 위해서는 총 N번의 lock(), unlock()이 필요하게 되어 이에 따른 오버헤드가 커진다는 점입니다.
따라서, 아래와 같이 각 쓰레드에 할당하는 구간의 사이즈를 1보다 크게 하여 lock(), unlock()에 드는 오버헤드를 줄일 수 있습니다. 하지만 이는 결국 Trade-Off로 각 쓰레드에게 할당되는 작업량의 편차가 생길 수 있죠. 왜냐하면 맨 앞의 1000개 원소에 드는 작업량이 맨 뒤의 1000개 원소에 드는 작업량보다 훨~씬 클 수 있으니까요.
#include <iostream>
#include <thread>
#include <vector>
void worker(int* input, int start, int size, int* output){
while(i < N){
global.lock();
i = counter;
counter += 1000; // worksize = 1000;
global.unlock();
do_something_on(input[i], 1000);
}
}
그래서 결국, Dynamic Assignment는 각 쓰레드에 대해 어느 정도 사이즈로 작업을 할당할 것인가에 대한 고민이 남게 됩니다. 너무 작은 단위로 나누면 Overhead가 커지고, 너무 큰 단위로 나누면 작업량의 불균형이 생길 수 있는 것이죠.
따라서 이 방식을 통해 멀티쓰레드를 할 때는 결국 여러 번의 시도를 통해 최적의 Granularity를 찾아내야 합니다.
4. Guided Assignment
Guided Assignment는 한국말로 어떻게 정의해야 할 지 모르겠습니다.
이 방식은 동적 할당과 비슷하지만 동적 할당은 각 쓰레드에게 위임하는 작업량의 단위(Granularity)가 고정되어 있다면, Guided Assignment는 이 사이즈가 유동적으로 변한다는 차이가 있습니다.
예를 들어, 작업을 할당하는 매 Iteration마다 처음에는 Granularity = 32로 주다가 후반부로 가면 Granularity = 1로 주는 것이죠. 이렇게 하면 처음에는 lock(), unlock()에 드는 오버헤드가 줄어들게 되고 좀 더 큰 단위로 작업을 할당하게 되지만, 후반부로 갈수록 작은 단위로 작업을 할당하면서 오버헤드를 어느정도 감수하는 대신 쓰레드 간의 작업 불균형을 맞춰주는 것이죠.
지금까지 이야기한 Static, Dynamic, Guided Assignment를 통한 쓰레드의 작업을 정리하면 아래 그림과 같습니다.
5. Thread Pool
5-1. Thread Pool이 왜 필요한가?
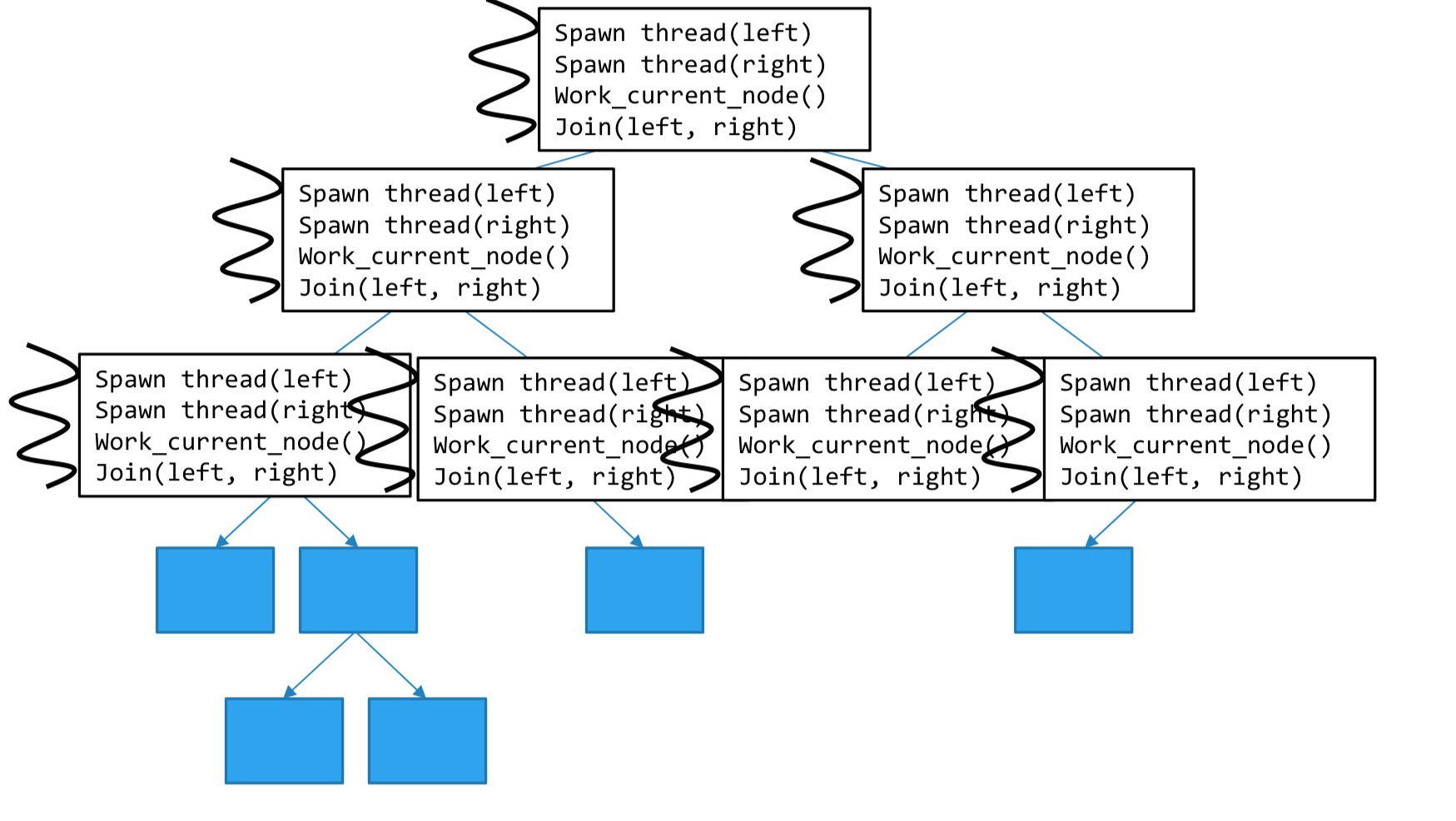
먼저 아래와 같이 root를 기준으로 뻗어나가는 트리가 있다고 해보겠습니다. 이 트리의 각 노드에는 특정한 작업들이 배정되어 있고, 우리는 쓰레드를 이용하여 트리를 순회하면서 각 작업을 처리해야 합니다.
그렇다면 이 상황에서는 어떻게 각 쓰레드에 작업을 할당할 수 있을까요?
위에서 배운 것처럼 Static Assignment를 한다면 트리를 어떻게 쪼개서 각 부분을 쓰레드에게 할당할 지가 쉽지 않은 문제이고, Dynamic Assignment를 시도하려해도 counter 변수를 노드 단위에 적용하기 어렵습니다.
즉, 각각의 Job들이 인덱스로 이루어진 것이 아니라 트리 구조로 이루어져 있다보니 트리의 순회(DFS, BFS)를 반드시 선행해야 한다는 단점이 생기는 것이죠.
그래서 이전에 배운 방식 대신, 아래와 같이 재귀적으로 쓰레드들을 생성하여 각 노드를 배정하는 방법을 생각해볼 수 있는데요.
하지만 이 방식은 정말 단순하게 생각해봐도 노드가 백 만개인 트리를 생각했을 때 쓰레드의 개수가 걷잡을 수 없이 늘어난다는 문제점이 있습니다. 그리고 이는 결국 잦은 Context Switching을 유발합니다. 그리고 Context Switching은 기본적으로 메모리에 접근하는 행위이기 때문에 CPU - Memory 사이의 Access 시간으로 인한 엄청난 오버헤드를 발생시키게 되죠.
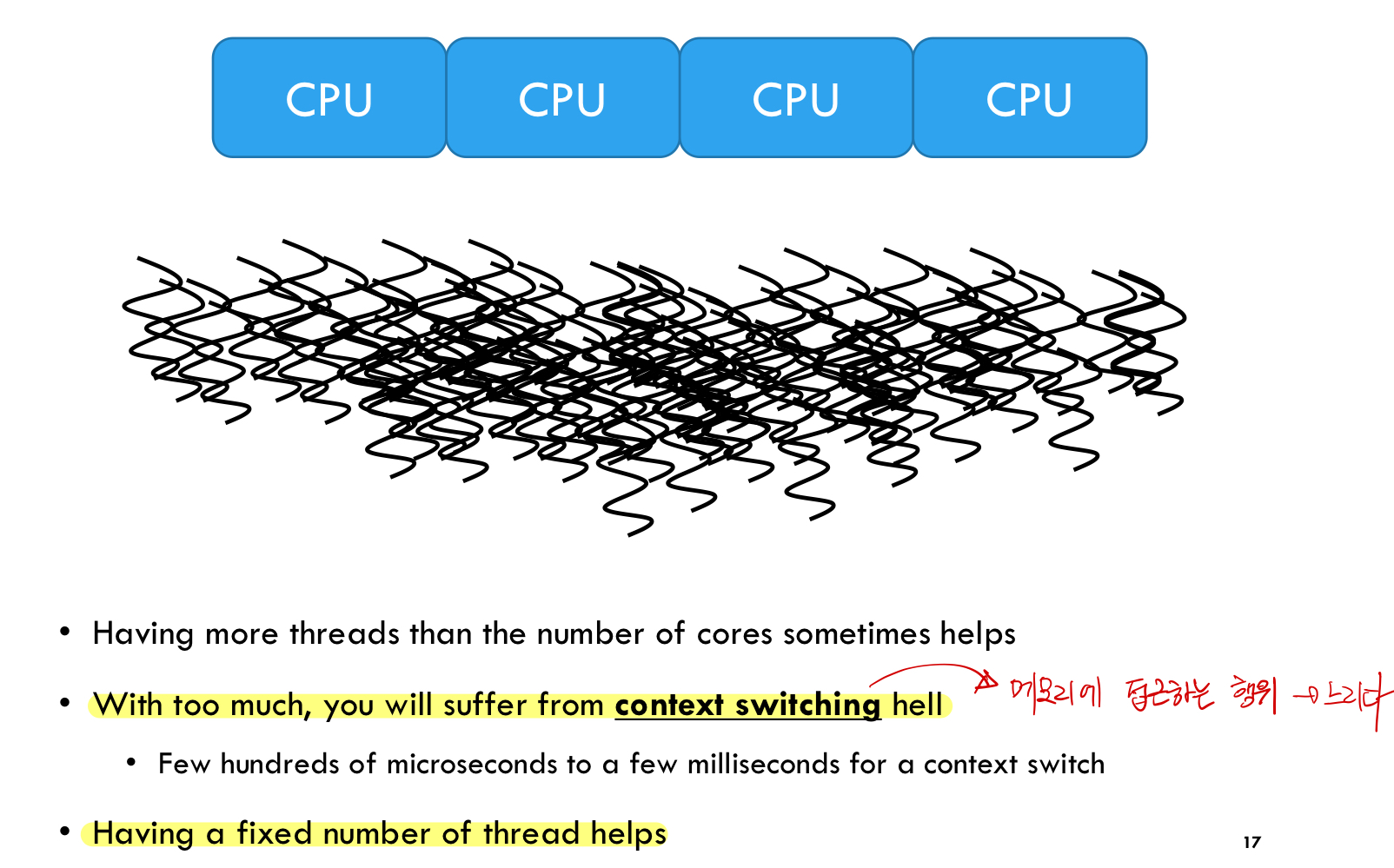
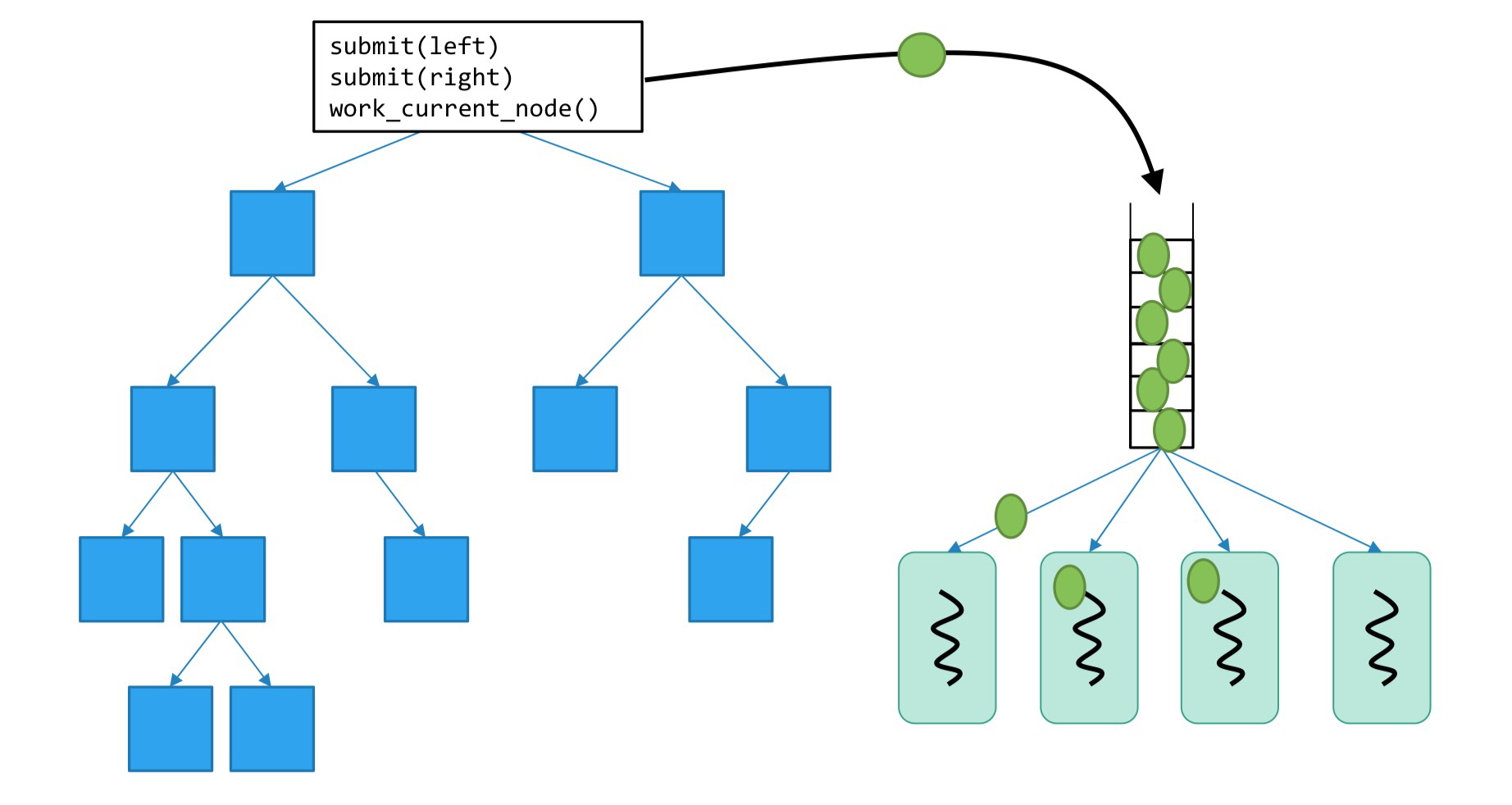
따라서, 이 문제를 해결하기 위해 Thread Pool이라는 개념을 이야기하려고 합니다.
Thread Pool은 Concurrent Queue에 해야하는 작업들을 Push하고, 미리 생성해둔 쓰레드 중에서 놀고 있는 쓰레드에게 각 작업을 Pop하여 할당하는 방식입니다. 이렇게 하면 일정한 쓰레드를 이용해서 동적으로 작업들을 처리할 수 있게 되죠.
5-2. ThreadPool 써보기
아래와 같은 모양의 트리가 있고, 우리는 8개의 쓰레드 풀을 생성하여 각 노드 번호에 제곱 연산을 하는 병렬 프로그램을 작성한다고 해보겠습니다.
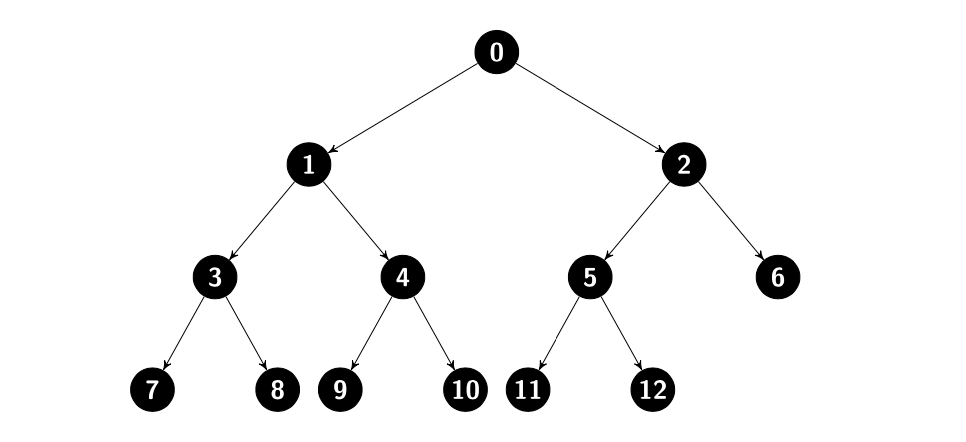
전위 순회를 한다고 가정했을 때, 0 → 1 → 3 → 7 → 8 → ... → 12 → 6 순서로 노드를 방문하겠죠?
먼저 쓰레드풀을 사용하기 위해 ThreadPool 클래스를 작성합니다(C++11 환경에서 boost 라이브러리를 깔아도 threadPool을 사용하기가 편하진 않았습니다).
#ifndef THREAD_POOL_H
#define THREAD_POOL_H
#include <vector>
#include <queue>
#include <memory>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <future>
#include <functional>
#include <stdexcept>
class ThreadPool
{
public:
ThreadPool(size_t);
template <class F, class... Args>
auto enqueue(F &&f, Args &&...args)
-> std::future<typename std::result_of<F(Args...)>::type>;
~ThreadPool();
private:
// need to keep track of threads so we can join them
std::vector<std::thread> workers;
// the task queue
std::queue<std::function<void()>> tasks;
// synchronization
std::mutex queue_mutex;
std::condition_variable condition;
bool stop;
};
// the constructor just launches some amount of workers
inline ThreadPool::ThreadPool(size_t threads)
: stop(false)
{
for (size_t i = 0; i < threads; ++i)
workers.emplace_back(
[this]
{
for (;;)
{
std::function<void()> task;
{
std::unique_lock<std::mutex> lock(this->queue_mutex);
this->condition.wait(lock,
[this]
{ return this->stop || !this->tasks.empty(); });
if (this->stop && this->tasks.empty())
return;
task = std::move(this->tasks.front());
this->tasks.pop();
}
task();
}
});
}
// add new work item to the pool
template <class F, class... Args>
auto ThreadPool::enqueue(F &&f, Args &&...args)
-> std::future<typename std::result_of<F(Args...)>::type>
{
using return_type = typename std::result_of<F(Args...)>::type;
auto task = std::make_shared<std::packaged_task<return_type()>>(
std::bind(std::forward<F>(f), std::forward<Args>(args)...));
std::future<return_type> res = task->get_future();
{
std::unique_lock<std::mutex> lock(queue_mutex);
// don't allow enqueueing after stopping the pool
if (stop)
throw std::runtime_error("enqueue on stopped ThreadPool");
tasks.emplace([task]()
{ (*task)(); });
}
condition.notify_one();
return res;
}
// the destructor joins all threads
inline ThreadPool::~ThreadPool()
{
{
std::unique_lock<std::mutex> lock(queue_mutex);
stop = true;
}
condition.notify_all();
for (std::thread &worker : workers)
worker.join();
}
#endif
그리고 아래와 같이 8개의 쓰레드를 생성하여 쓰레드 풀 안에 담아두고, 전위 순회를 통해 각 노드의 작업을 처리해보겠습니다.
#include <iostream>
#include "ThreadPool.h"
#include <vector>
#include <future>
ThreadPool TP(8); // 8 threads in a pool
int main()
{
// function to be processed by threads
auto square = [](const uint64_t x)
{
return x * x;
};
const uint64_t num_nodes = 13;
std::vector<std::future<uint64_t>> futures;
// preorder binary tree traversal
typedef std::function<void(uint64_t)> traverse_t;
traverse_t traverse = [&](uint64_t node)
{
if (node < num_nodes)
{
// submit the job
auto future = TP.enqueue(square, node);
futures.emplace_back(std::move(future));
// traverse a complete binary tree
traverse(2 * node + 1); // left child
traverse(2 * node + 2); // right child
}
};
traverse(0);
// get the results
for (auto &future : futures)
std::cout << future.get() << std::endl;
}위 코드를 컴파일하고 실행하면 아래와 같이 우리가 원하는 결과가 나오는 것을 확인할 수 있습니다.
6. 나가면서
이번 시간에는 멀티쓰레드 환경에서 각 쓰레드들의 워크로드를 적절히 분산하여 병렬 프로그래밍의 효율성을 보장하는 방법에 대해 공부해봤습니다.
Static, Dynamic Assignment를 통한 쓰레드의 작업 할당에 대해 공부해봤고, Guided Assignment를 통해 Dynamic Assignment의 고정 사이즈를 변동시키는 방법에 대해서도 공부했습니다.
마지막으로는 이러한 방식으로도 쓰레드의 작업 할당이 어려운 상황에서 쓰레드 풀을 활용하여 동적으로 작업을 할당하는 방법에 대해 공부하고 실습까지 해봤습니다.
앞으로의 다른 포스팅에서도 아마 쓰레드 풀에 대해 공부할 시간이 더 있을 것 같은데요. 이번 시간에 정리한 내용을 잘 기억해서 멀티쓰레드 환경에서 각 쓰레드가 책임지는 역할에 대해 관심있게 봐야 할 것 같습니다.
감사합니다.
'CS > Multicore & GPU' 카테고리의 다른 글
| [Multicore] 효율적인 Matrix Multiplication - 멀티쓰레드와 캐시 (0) | 2022.04.19 |
|---|---|
| [Multicore] Race Condition과 Locks (0) | 2022.03.11 |



