
[운영체제/OS] 디스크 구조와 I/O 작업 스케줄링
kindof
·2021. 6. 14. 20:50
💡0. 들어가면서
이전 포스팅까지 OS의 메모리 관리 기법에 대해 살펴봤습니다. 험난한 길이었습니다.

이번 시간부터는 OS가 어떻게 디스크를 탐색하는지에 대해 공부해보려고 하는데요. 먼저 구글에 '하드디스크'라고 검색해보면 아래와 같은 사진들을 보실 수 있습니다.
그렇다면 우리의 OS는 어떤 방식으로 디스크의 데이터를 읽고 저장할 수 있을까요?
📒 1. 디스크의 구조
아래는 일반적인 디스크의 구조입니다.
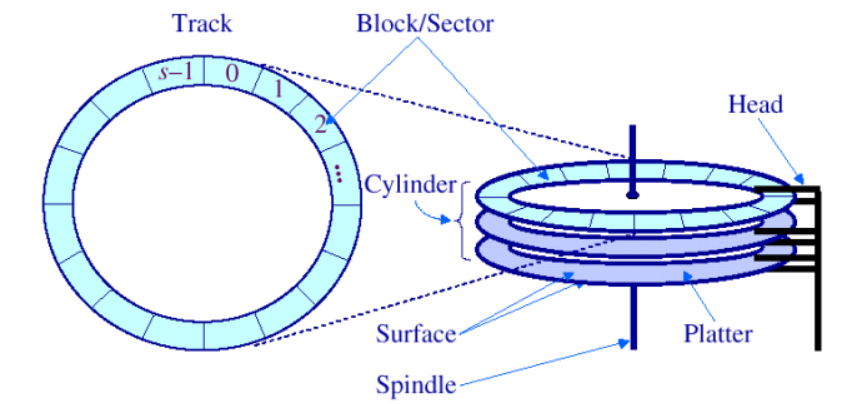
디스크는 크게 Cylinder, Platter, Track, Sector, Head로 구성되어 있습니다. Cylinder는 우리말로 원통이고 Platter는 평평한 원판을 의미하죠? 그래서 N장의 Platter를 겹쳐놓은 것을 Cylinder라고 하며, 각 Platter에 대해 Head가 존재하는 구조라고 이해할 수 있습니다.
또한, 각 Flatter는 왼쪽 그림과 같이 Track, Sector로 구성되어 있는데요. Track은 Platter의 중심으로부터 일정거리 떨어진 Sector들의 집합입니다. 그러면 중심으로부터 멀리 떨어진 Track에 위치한 Sector들은 중심에 있는 녀석들보다 크기가 크겠죠?
자, 그러면 이제 어떻게 각각의 Platter > Sector 안에 데이터를 읽고 쓸까요?
📖 2. 디스크에 Read/Write 작업하기
위에서 말씀드렸듯이, 하나의 플래터에는 헤드가 존재합니다. 이 헤드를 이용해 디스크에 읽고 쓰는 작업을 하기 위해서는 크게 세 단계를 거치는데요.
1) 헤드를 통해 우리가 원하는 타겟 트랙을 찾고
2) 트랙을 찾았으면 디스크가 회전하면서 원하는 섹터가 오기까지 기다립니다.
3) 해당 섹터가 헤드에 위치하게 되면 데이터를 읽고 쓸 수 있게 되죠.
이 때 각각의 동작을 위해 소요되는 시간을 순서대로 Seek Time, Rotational Latency, Transfer Time이라고 합니다. 즉, 디스크에 Read/Write 작업을 하는 데 드는 총 시간은 이 시간들의 합으로 정의될 수 있죠.
Read/write Time = seek time + latecny + transfer time
📬 3. 디스크의 주소(Disk Addressing)
디스크 안에 있는 데이터들은 (# Platter, # Track. # Sector)라는 주소를 갖습니다. 즉, (몇 번째 원판, 몇 번째 트랙, 몇 번째 섹터)라는 주소지를 가지고 있다는 것이죠. 이 정보를 모두 알아야 원하는 디스크 주소를 찾아서 Read/Write 작업을 할 수 있습니다.
그런데 사실 디스크는 여러 개의 실린더로 구성될 수 있습니다. 이를 통해 각 실린더마다 존재하는 헤드들을 이용해서 데이터를 동시에 읽고 쓸 수 있게 되죠. 따라서 플래터, 트랙, 섹터의 주소만을 가지고는 "몇 번째 실린더에 있는 데이터인가?"를 알 수 없습니다. 그래서 아래와 같은 방식을 이용해서 완전한 디스크의 주소를 찾아가야 합니다.

형광색으로 표시한 부분을 오른쪽부터 읽어나가면 이해하기 편한데요. 위의 주소 표기 방식은 결국 가장 작은 섹터 단위의 주소로 변환하는 과정입니다.
📊 4. 디스크 스케줄링(Disk Scheduling)
위에서 말씀드렸듯, OS가 디스크에 대한 Read/Write 작업을 할 때는 Seek Time + Rotational Latency + Transfer Time만큼의 시간이 소요됩니다. 특히 이 중에서 헤드가 움직이는 시간(Seek Time)이 가장 주요하기 때문에 헤드의 움직임을 최소화하는 것이 디스크 스케줄링에서 가장 중요한데요.
헤드의 움직임은 I/O 작업들의 스케줄링 방식에 따라 달라지기 때문에 I/O 작업의 스케줄링 방식에 따라 헤드의 움직임이 어떻게 변하는지 살펴봐야 합니다.
✅ 4-1) FCFS 스케줄링
가장 먼저 들어온 I/O 작업을 먼저 처리하는 방식입니다.
먼저 들어온 녀석을 먼저 처리하기 때문에 스케줄링에 대한 오버헤드가 없고 계속 대기해야 하는 작업도 없죠. 하지만 아래 그림에서 알 수 있다시피, 헤드가 계속 와리가리를 칩니다. 성능이 매우 안좋겠죠. 따라서 FCFS 스케줄링 방식은 디스크 접근 부하가 적은 경우에만 적합한 스케줄링이라고 볼 수 있습니다.

✅ 4-2) SSTF 스케줄링
SSTF 스케줄링은 현재 헤드에서 가장 가까운 섹터에 있는 I/O 작업 대상부터 처리하는 방법인데요.
이 장점은 Throughput이 좋고 평균 응답 시간이 작다는 장점이 있습니다. 하지만 헤드로부터 멀리 떨어진 I/O 작업은 한참을 기다려야 하는 문제점이 있습니다. 결국 이 방식은 메모리 Throughput이 높아야하거나, 일괄처리 시스템을 위한 디스크에 적합한 방식입니다.

✅ 4-3) SCAN 스케줄링
SCAN 스케줄링은 엘리베이터처럼 현재 위치에서 쭉 내려갔다가 쭉 올라가는 방식 혹은 쭉 올라갔다가 쭉 내려가는 방식으로 스케줄링합니다. 그래서 엘리베이터 알고리즘이라고도 불리는데요.
SCAN 스케줄링을 수행할 때는 현재 헤더의 위치와 어느 방향으로 먼저 탐색할 지를 정해야 하고 탐색 방향에 따라 수행되는 작업의 순서가 달라집니다.
장점은 위에서 소개한 SSTF 방법에서 발생하는 Starvation 문제를 해결할 수 있다는 점과 응답시간이 적게 걸린다는 점인데요. 하지만 진행방향에 따라서 진행 반대쪽 끝에 있는 녀석의 응답시간은 가장 길어질 수밖에 없고, 만약 이 작업이 정말 크리티컬한 작업이라면 시스템 상에서 손해가 발생할 수 있습니다.

✅ 4-4) C-SCAN 스케줄링(Circular SCAN)
C-SCAN 스케줄링은 아래 그림처럼 한 쪽 방향으로만 헤드를 움직입니다. 이 방법 역시 최초에 현재 헤더의 위치와 탐색 방향을 알아야하죠.
일반적인 SCAN 스케줄링에서는 진행 방향 반대편에 있는 녀석이 굉장한 손해를 봤는데, 여기서는 모든 작업이 비슷한 수준의 응답 시간을 유지할 수 있는 장점이 있습니다.

✅ 4-5) LOOK / C-LOOK 스케줄링
LOOK 스케줄링에서 기본적인 헤드의 움직임은 SCAN과 같지만, 트랙의 양끝을 찍지 않고 최대/최소 범위에서만 움직입니다. 그리고 C-LOOK은 최대/최소 범위 안에서 한 쪽 방향으로만 헤드를 진행시킵니다.


지금까지 디스크의 기본적인 구조와 주소 매핑 방식, 그리고 다섯가지 I/O 작업의 스케줄링 방법에 대해 살펴봤습니다.
이어서 다음 시간에는 디스크의 관리에 대해 공부해보겠습니다.

'CS > OS' 카테고리의 다른 글
| [운영체제/OS] 동기화 이슈 처리하기 - (2) (2) | 2021.09.24 |
|---|---|
| [운영체제/OS] 시스템 콜(System Call)에 대한 간단한 정리 (0) | 2021.09.23 |
| [운영체제/OS] 프레임 할당(Frame allocation)과 Page fault 관련 기타 이슈들 (1) | 2021.06.14 |
| [운영체제/OS] 여러가지 페이지 교체 정책에 대해 (0) | 2021.06.14 |
| [운영체제/OS] 메모리 관리 - 디맨드 페이징과 페이지 부재(Page Fault) Issue (0) | 2021.06.14 |





