
[코틀린 인 액션] 5장, 람다로 프로그래밍
kindof
·2023. 8. 20. 23:21
[코틀린 인 액션] 책을 읽으면서 이해한 내용을 정리합니다.
책의 설명을 기반으로 하되, Java와의 비교나 주관적인 생각들도 써보려고 하는데요. 코드를 작성하면서 궁금한 부분이나 다른 기본적인 내용들은 최대한 공식 문서를 참고해서 작성해보겠습니다.
이번 시간에는 코틀린에서 람다를 사용하는 여러 예제 코드를 살펴보려고 합니다.
사실 이번 장은 Java 8 이후의 람다에 대해 공부해보셨다면, 크게 새로운 부분은 없다고 생각합니다.
설명하는 코드는 책에서 소개한 코드에 기반하여 설명을 위해 조금씩 각색 + 추가한 부분이 있을 수 있습니다.
1. 람다식 이해하기
코틀린에서 람다식을 사용하는 방식에 대해 이해해보기 위해 책에서 소개하지 않은 코틀린 공식 문서의 코드를 소개합니다.

먼저, 위 코드는 고차 함수와 람다식을 다룹니다. 고차 함수는 함수를 매개변수로 받거나, 함수를 반환하는 함수인데요. 코드의 각 부분에 대해 나눠서 설명하겠습니다.
[1] fold 메서드는 기본적으로 Collection에 대한 확장 함수라는 것을 알 수 있습니다. 그리고 두 개의 매개변수를 받는데, 'combine' 파라미터는 함수 타입 (R, T) -> R 형태를 가지고 있습니다.
[2] initial 값은 fold 작업에 대한 초기값이고, combine은 람다식입니다. 이 함수는 두 개의 매개변수 (acc, nextElement)를 받아서 새로운 누적 값을 계산하고 반환합니다.
[3] 람다식은 { } 안에 정의됩니다. acc, i 라는 두 개의 파라미터를 받아 '->' 표시를 통해 수행할 작업을 정의합니다. 여기서는 initial = 0, acc = 0, i = 1로 시작하여 items 원소에 대한 누적값을 계산하고 출력합니다.
[4] initial 값을 "Elements:" 라는 문자열로 시작합니다. 반환값으로는 "$acc $i" 라는 문자열이 주어졌으니, "Elements:" 문자열에 items 원소의 값들이 이어질 것입니다.
[5] 초기값을 1로 시작하여, 멤버 참조(member reference)를 통해 items의 각 원소를 곱한 값을 계산하고 있습니다.
위 코드를 이해하고 아래 출력 결과를 예측할 수 있다면, 기본적인 람다식의 동작을 잘 이해하고 있다고 생각합니다.
// Output
acc = 0, i = 1, result = 1
acc = 1, i = 2, result = 3
acc = 3, i = 3, result = 6
acc = 6, i = 4, result = 10
acc = 10, i = 5, result = 15
joinedToString = Elements: 1 2 3 4 5
product = 120
2. 컬렉션 함수형 API
코틀린에서 컬렉션을 다루는 함수형 API 몇 가지에 대해 소개합니다.
기본적으로 Java에서도 비슷한 내용들이 있기 때문에 가볍게 살펴보고 넘어가도 될 것 같습니다.
data class PersonV2(val name: String, val age: Int)
fun main() {
val people = listOf(
PersonV2("Alice", 25),
PersonV2("Bob", 30),
PersonV2("Charlie", 22),
PersonV2("David", 28),
PersonV2("Eve", 35)
)
// Filter: 나이가 30 이상인 사람들을 필터링
val olderThan30 = people.filter { it.age >= 30 }
// Map: 각 사람의 이름만 추출하여 새로운 리스트 생성
val names = people.map { it.name }
// All: 모든 사람이 20세 이상인지 검사
val allAbove20 = people.all { it.age >= 20 }
// Any: 어느 한 사람이라도 30세 이상인지 검사
val anyAbove30 = people.any { it.age >= 30 }
// GroupBy: 나이별로 그룹화하여 맵 생성
val ageGroups = people.groupBy { if (it.age < 25) "Under 25" else "25 and above" }
// FlatMap: 각 사람의 이름을 문자 리스트로 분리하여 하나의 리스트로 평면화
val nameLetters = people.flatMap { it.name.toList() }
// Flatten: 리스트 중첩을 해제하여 하나의 리스트로 만듦
val nestedList = listOf(listOf(1, 2, 3), listOf(4, 5, 6), listOf(7, 8, 9))
val flattenedList = nestedList.flatten()
println("People older than 30: $olderThan30")
println("Names: $names")
println("All people above 20: $allAbove20")
println("Any person above 30: $anyAbove30")
println("Age groups: $ageGroups")
println("Name letters: $nameLetters")
println("Flattened list: $flattenedList")
}
3. 지연 계산(lazy) 컬렉션 연산
The mapping transformation creates a collection from the results of a function on the elements of another collection. The basic mapping function is map(). It applies the given lambda function to each subsequent element and returns the list of the lambda results.
The basic filtering function is filter(). When called with a predicate, filter() returns the collection elements that match it. For both List and Set, the resulting collection is a List, for Map it's a Map as well.
코틀린 공식 문서에서는 위처럼 filter, map이 리스트를 반환하다고 말합니다. 만약, 수백만 개의 원소를 가진 리스트에 대해 filter, map 함수를 적용하면 꽤 커다란 객체 두 개가 생성되는 문제가 있죠.
코틀린에서는 이를 더 효율적으로 만들기 위해 각 연산이 컬렉션을 직접 사용하는 대신 시퀀스를 사용합니다.
Sequence 인터페이스는 iterator라는 단 하나의 메서드가 있는데, 이 메서드를 통해 시퀀스로부터 원소 값을 얻을 수 있습니다.
public interface Sequence<out T> {
/**
* Returns an [Iterator] that returns the values from the sequence.
*
* Throws an exception if the sequence is constrained to be iterated once and `iterator` is invoked the second time.
*/
public operator fun iterator(): Iterator<T>
}
시퀀스의 원소는 필요할 때 비로소 계산되기 때문에 중간 처리 결과를 저장하지 않고도 연산을 연쇄적으로 적용해서 효율적으로 계산을 수행하는데요. 아래 코드를 보겠습니다.
fun main() {
println("중간 연산만 있을 경우 아무 내용이 출력되지 않는다.")
listOf(1,2,3,4).asSequence()
.map {print("map($it) "); it * it}
.filter { print("filter($it) "); it % 2 == 0 }
println("#####################################")
println("최종 연산에서 모든 계산이 수행된다.")
listOf(1, 2, 3, 4).asSequence()
.map { print("map($it) "); it * it }
.filter { print("filter($it) "); it % 2 == 0 }
.toList()
}
// Output
중간 연산만 있을 경우 아무 내용이 출력되지 않는다.
#####################################
최종 연산에서 모든 계산이 수행된다.
map(1) filter(1) map(2) filter(4) map(3) filter(9) map(4) filter(16)위 코드의 실행 결과를 보면 알 수 있는 것처럼, 시퀀스의 경우 모든 연산은 각 원소에 대해 순차적으로 적용됩니다. 즉, 첫번째 원소가 처리되고, 다시 두 번째 원소가 처리되며 이런 처리가 모든 원소에 대해 적용됩니다.
한편, 책에서는 map(), filter()의 순서에 따른 성능 차이에 대해서도 소개합니다.
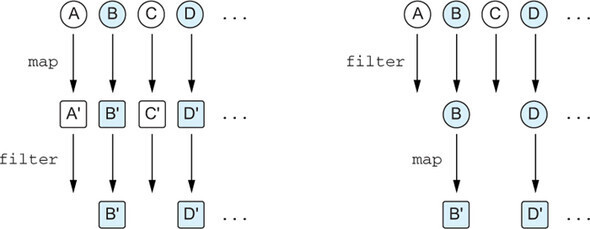
실제 서비스 코드를 작성할 때도 이러한 로직이 많이 있기 때문에 filter() 다음에 map()을 적용하는 습관을 가져두면 좋을 것 같습니다.
4. with, apply
코틀린 표준 라이브러리에는 with, apply라는 수신 객체 지정 람다(lambda with receiver)가 존재합니다.
먼저 아래 코드를 통해 with에 대해 살펴봅니다.
import java.lang.StringBuilder
fun alphabet(): String {
val result = StringBuilder()
for (letter in 'A'..'Z') {
result.append(letter)
}
result.append("\nNow I know the alphabet!")
return result.toString()
}
fun main() {
println(alphabet())
}
// Output
ABCDEFGHIJKLMNOPQRSTUVWXYZ
Now I know the alphabet!이 예제에서는 result에 대해 다른 여러 메서드를 호출하면서 매번 result를 반복 사용합니다. 이 정도 반복은 대수롭지 않아 보이지만, 코드가 훨씬 길거나, result를 더 자주 반복해야 한다면 번거로울 수 있습니다.
이 예제를 with를 사용해 리팩토링 해보겠습니다.
fun alphabet(): String {
val stringBuilder = StringBuilder()
return with(stringBuilder) {
for (letter in 'A'..'Z') {
this.append(letter)
}
append("\nNow I know the alphabet!")
this.toString()
}
}with문은 첫번째 파라미터로 stringBuilder를 받고 두번째 파라미터로 람다식을 받습니다. 즉, 첫번째 인자로 받은 객체를 두번째 인자로 받은 람다식의 수신 객체로 만드는 것인데요.
인자로 받은 람다 본문에서는 this를 사용해 그 수신 객체에 접근할 수 있게 됩니다. 그리고 일반적인 this와 마찬가지로 this와 점(.)을 사용하지 않고 프로퍼티나 메서드 이름만 사용해도 수신 객체의 멤버에 접근할 수 있습니다.
다음으로 apply 함수에 대해 살펴보겠습니다.
apply 함수는 with와 거의 비슷하지만, 항상 자신에게 전달된 객체(수신 객체)를 반환한다는 차이점을 갖습니다.
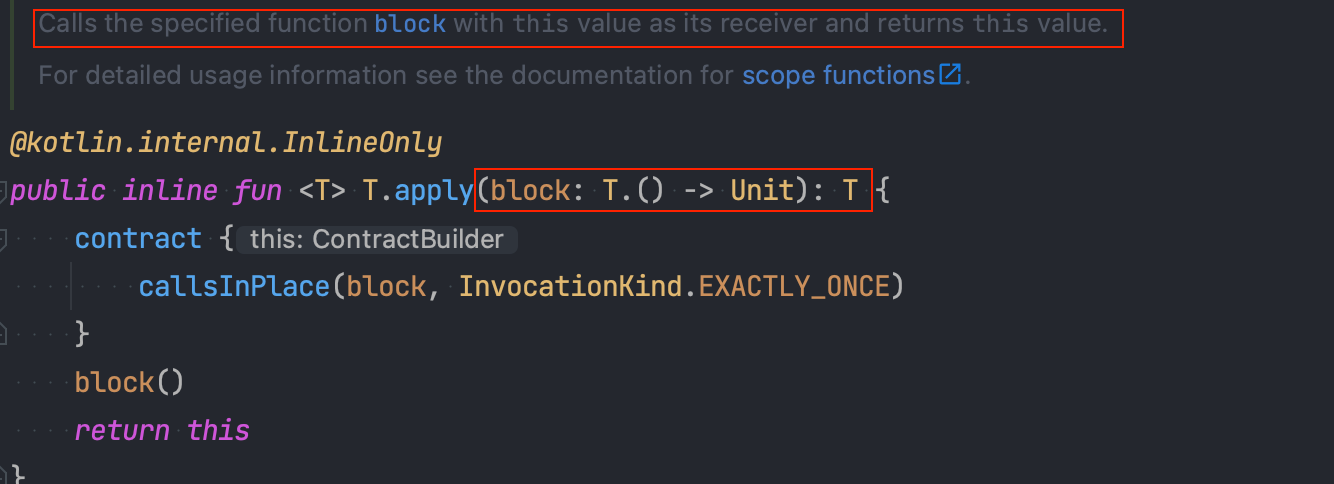
실제 apply 함수는 제네릭 타입 T를 받고, 함수의 반환 타입과 인자로 받는 람다의 타입 모두 T입니다. 즉, 수신 객체(this)에 대해 람다 블록을 실행하고, 람다 블록의 결과로 수신 객체 this를 반환하는 것이죠.
그럼, 위에서 작성한 alphabet 메서드를 apply 함수를 사용해서 바꿔보겠습니다.
fun alphabet() = StringBuilder().apply {
for (letter in 'A'..'Z'){
append(letter)
}
append("\nNow I know the alphabet!")
}.toString()apply를 실행한 결과는 StringBuilder 객체이기 때문에 StringBuilder 객체의 toString을 호출해서 String 객체를 얻어왔습니다.
5. 정리 / Reference
이번 글에서는 코틀린의 람다 프로그래밍에 대해 다뤄봤습니다.
Java에서 사용했던 람다식과 크게 다른 부분은 없지만, 코틀린에서 조금 더 편하게 사용할 수 있는 몇 가지 기능이 있었던 것 같습니다.
다음 시간에는 코틀린의 정말 중요한 부분인 타입 시스템에 대해 소개하겠습니다.
감사합니다.
High-order functions and lambdas | Kotlin
kotlinlang.org
Kotlin in Action | 드미트리 제메로프 - 교보문고
Kotlin in Action | 코틀린이 안드로이드 공식 언어가 되면서 관심이 커졌다. 이 책은 코틀린 언어를 개발한 젯브레인의 코틀린 컴파일러 개발자들이 직접 쓴 일종의 공식 서적이라 할 수 있다. 코틀
product.kyobobook.co.kr
'Java & Kotlin' 카테고리의 다른 글
| ThreadLocal을 사용할 때 주의할 점 (1) | 2023.10.22 |
|---|---|
| [코틀린 인 액션] 6장, 코틀린 타입 시스템 (0) | 2023.08.20 |
| [코틀린 인 액션] 4장, 클래스, 객체, 인터페이스 (0) | 2023.08.18 |
| [코틀린 인 액션] 3장, 함수 정의와 호출 (0) | 2023.08.15 |
| [코틀린 인 액션] 2장, 코틀린 기초(함수와 변수, ..., 코틀린의 예외 처리) (0) | 2023.08.14 |





