
[네트워크/Network] IPv4 데이터그램의 형식과 단편화(Fragmentation)
kindof
·2021. 10. 12. 15:46
💡 0. 들어가면서
이전에 OSI 7계층에 대해 공부하면서 정리한 내용 중에 일부를 가져와봤는데요. 아래 설명처럼 네트워크 계층은 출발지 호스트에서 트랜스포트 계층 프로토콜(TCP, UDP)의 세그먼트를 받아서 캡슐화하고 전달합니다. 그리고 이 때 네트워크 계층에서 움직이는 패킷을 "데이터그램"이라고 하죠.

그래서 이번 시간에는 IPv4 데이터그램의 형식에 대해 살펴보고 단편화(Fragmentation)라는 개념에 대해 알아보려고 합니다. 그리고 이 후 포스팅에서는 IPv4의 주소체계에 대해 공부해보고 IPv6에 대한 내용까지 공부해보겠습니다.
이번 포스팅에서는 IPv4 기반 데이터그램의 형식과 각 필드가 어떤 역할을 하는지, 그리고 데이터그램이 링크 계층을 통해 전달될 때 '프레임'이라는 단위로 단편화(Fragmentation)되는데 '단편화'는 왜 필요한지를 이해하는 데 집중해서 읽어보시면 좋겠습니다.
📋 1. IPv4 데이터그램 형식
일단 네트워크 계층과 IP 프로토콜에 대해 공부하기 위해서는 우선 데이터그램이 어떻게 생겼는지를 알아야겠죠?
IPv4 데이터그램은 아래와 같은 포맷으로 이루어져 있습니다. 각 파트가 어떤 정보를 담고 있는지 보겠습니다. 중요한 부분이니 잘 봐주세요⭐️
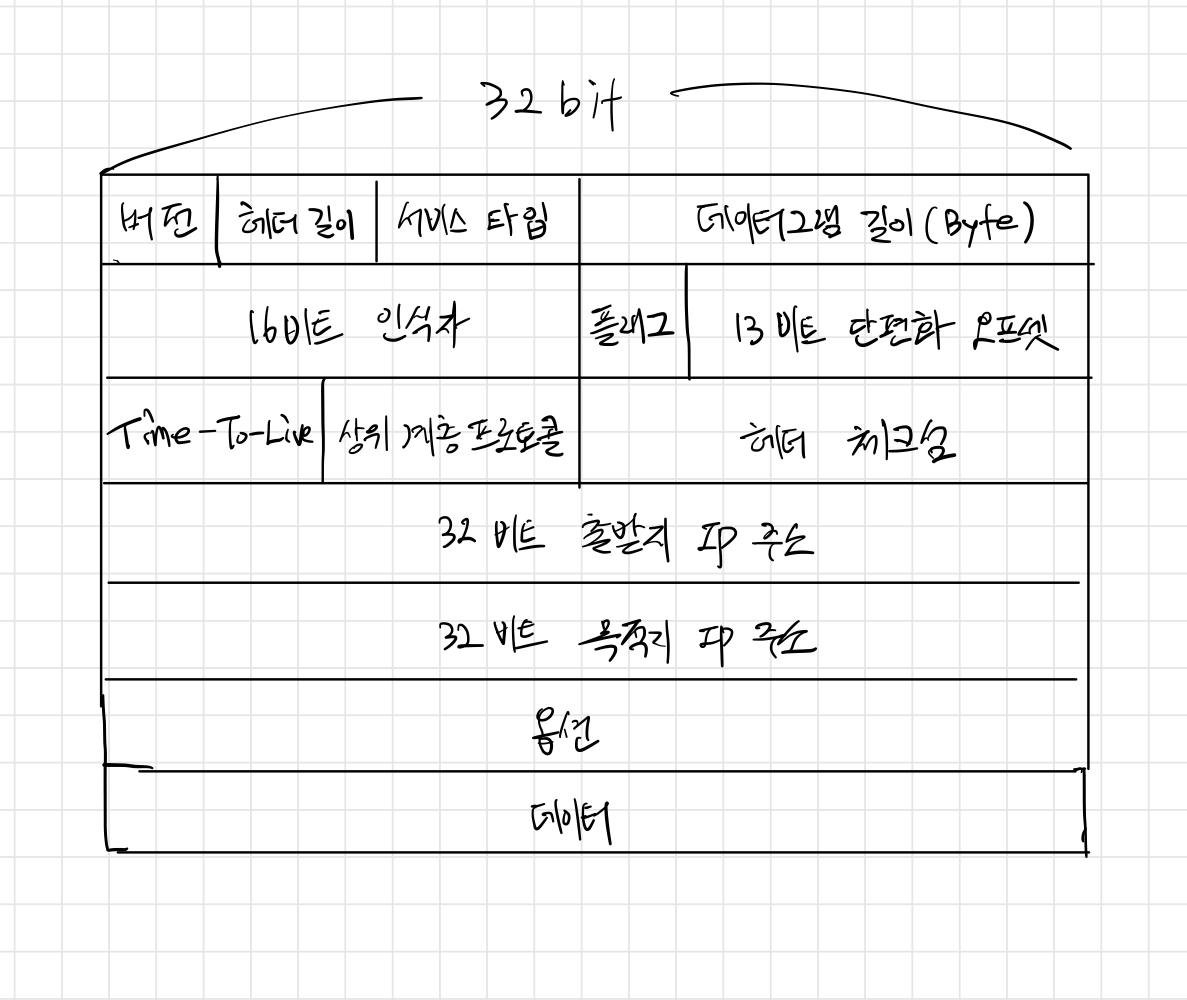
버전 번호: 4비트로 데이터그램의 IP 프로토콜 버전을 명시합니다. 다른 버전의 IP는 다른 데이터그램 형식을 사용하기 때문에 라우터는 버전 번호를 확인하여 데이터그램의 나머지 부분을 어떻게 해석하는지 결정합니다.
헤더 길이: IPv4 데이터그램은 헤더에 가변 길이의 옵션을 포함하기 때문에 4비트의 헤더 길이를 통해 IP 데이터그램에서 실제 페이로드가 시작하는 곳을 명시해줍니다. 대부분 IPv4 데이터그램은 옵션을 포함하지 않아서 데이터그램의 헤더는 20바이트가 통상적입니다. 위 그림에서 <옵션> 부분을 없애면 32 bit씩 5줄이니까 20바이트라는 게 이해되시죠?
서비스 타입: 서비스 타입 비트는 서로 다른 유형의 IP 데이터그램을 구별합니다. 예를 들어, 실시간 데이터그램(IP 통신 어플리케이션)과 비실시간 트래픽(FTP)을 구분할 수 있죠.
데이터그램 길이: 바이트로 계산한 IP 데이터그램(헤더와 데이터)의 전체 길이입니다. 이 필드의 크기는 16비트이므로 IP 데이터그램의 이론상 최대 길이는 65,536(2^16)바이트이지만 1,500바이트보다 큰 경우는 거의 없으므로 최대 크기의 이더넷 프레임의 페이로드 필드에 IP 데이터그램이 장착될 수 있습니다.
식별자, 플래그, 단편화 오프셋: 세 필드는 IP 단편화와 관계가 있습니다. 뒤에서 자세히 설명하도록 하겠습니다.
TTL(Time-To-Live): 이 필드는 네트워크에서 데이터그램이 무한히 순환하지 않도록 합니다. 라우터가 데이터그램을 처리할 때마다 값을 감소시켜서 TTL 필드값이 0이 되면 라우터는 데이터그램을 폐기하죠.
상위 계층 프로토콜: 이 필드는 일반적으로 IP 데이터그램이 최종 목적지에 도달했을 때만 사용합니다. 이 필드값은 IP 데이터그램에서 데이터 부분이 전달될 목적지의 전송 계층의 특정 프로토콜을 명시하는데요. 예를 들어, 이 필드값이 "6"이면 데이터 부분을 TCP로, "17"이면 UDP로 데이터를 전달하라는 뜻이 됩니다.
헤더 체크섬: 헤더 체크섬은 라우터가 수신한 IP 데이터그램의 비트 오류를 탐지하는 데 도움을 줍니다. 비트 오류 탐지에 대한 메커니즘은 우선 건너뛰겠습니다.
출발지와 목적지 IP 주소: 출발지가 데이터그램을 생성할 때, 자신의 IP 주소를 출발지 IP 주소 필드에 삽입하고 목적지 IP 주소를 목적지 IP 주소 필드에 삽입합니다.
옵션: 옵션 필드는 IP 헤더를 확장합니다.
데이터(페이로드): 데이터그램이 존재하는 이유이자 가장 중요한 마지막 필드입니다. 대부분의 경우에 IP 데이터그램의 데이터 필드는 목적지에 전달하기 위해 전송 계층 세그먼트(TCP, UDP)를 포함하지만, ICMP 메시지와 같은 다른 유형의 데이터를 담기도 합니다.
위 내용을 종합해보면, IP 데이터그램은 총 20바이트의 헤더(옵션이 없을 때)를 갖습니다. 데이터그램이 TCP 세그먼트를 전송한다면 단편화가 되지 않은 각 데이터그램은 응용 계층의 메시지와 더불어 총 40바이트의 헤더(IP 헤더 20바이트, TCP 헤더 20바이트)를 전송합니다.
📝 2. IPv4 데이터그램의 단편화
💡 2-1) 단편(Fragment)은 무엇이고 왜 필요하지?
"IPv4 데이터그램의 단편화"에 대해 이해하기 위해서는 "왜 단편화가 필요한가?"를 알아야 하는데요. 단편화가 필요한 이유는 모든 링크 계층 프로토콜들이 같은 크기의 네트워크 계층 패킷을 전달할 수 없기 때문입니다. 어떤 프로토콜은 큰 데이터그램을 전달하는 반면에 다른 프로토콜은 작은 데이터그램만을 전달할 수 있죠. 예를 들어 이더넷 프레임은 최대 1,500바이트 데이터를 전달하지만, 광역 링크 프레임은 576바이트 이상의 데이터를 전달할 수 없습니다.
한편, 링크 계층 프레임이 전달할 수 있는 최대 데이터 양을 MTU(Maximum Transmission Unit)이라고 부릅니다. 각 IP 데이터그램은 한 라우터에서 다른 라우터로 전송하기 위해 링크 계층 프레임 내에 캡슐화되므로 링크 계층 프로토콜의 MTU는 IP 데이터그램 길이에 엄격한 제약을 둘 수밖에 없는 것이죠.
다시 말해, 한 링크에서 IP 데이터그램을 받으면 우리는 출력 링크를 결정하기 위해 전달 테이블을 검사하게 되는데 이때 출력 링크가 IP 데이터그램의 길이보다 작은 MTU를 가지면 당황스러운 상황에 마주하는 것입니다.
어떻게 이 커다란 IP 패킷을 링크 계층 프레임의 페이로드 필드에 짜맞출 수 있을까요? 그래서 이에 대한 해결책으로 IP 데이터그램의 페이로드를 두 개 이상의 더 작은 IP 데이터그램으로 분할하고, 각각의 더 작아진 IP 데이터그램을 별로의 링크 계층 프레임으로 캡슐화하여 출력 링크로 보내는 것입니다. 그리고 이러한 작은 데이터그램 각각을 조각(Fragment, 단편)이라고 합니다.
📚 2-2) Fragment의 전송과 결합
위와 같은 목적으로 쪼개진 IP 데이터그램 조각들은 목적지 전송 계층에 도달하기 전에 재결합되어야 합니다. 실제로 TCP, UDP 모두 네트워크 계층에서 단편화가 되지 않은 완벽한 세그먼트를 수신하는 것을 기대하죠.
하지만, IPv4 설계자는 라우터가 데이터그램을 재결합하면 프로토콜을 복잡하게 만들고 라우터 성능에 문제를 일으킬 것이라 생각했습니다. 왜 그럴까요?
라우터에서 데이터그램 조각을 재결합하면 안 되는 이유 중 하나는 하나의 모든 패킷이 하나의 라우터로 모이는 것이 아니기 때문입니다. 또한, 네트워크 코어를 간단하게 유지하기 위한 원칙을 고수하기 위함이기도 하죠.
어쨌든, 위와 같은 이유로 IPv4 설계자는 네트워크 라우터가 아닌 종단 시스템에서 데이터그램 재결합을 하도록 결정했습니다.
자, 이제 목적지 호스트가 같은 출발지로부터 일련의 데이터그램을 수신하면 이러한 데이터그램이 원본 데이터그램의 조각인지를 판단하고, 마지막 조각을 수신할 때 원본 데이터그램을 만들기 위해 조각을 결합하는 방법을 결정해야 합니다.
목적지 호스트가 이러한 재결합을 수행할 수 있도록 IPv4 설계자는 식별자, 플래그, 단편화 오프셋 필드를 IP 데이터그램 헤더에 찍어 넣었는데요(위에 데이터그램의 포맷을 참고해주세요).
일반적으로 송신 호스트에서 데이터그램을 보낼 때, 식별자 번호를 증가시켜서 데이터그램의 헤더에 써 넣습니다.
IP는 신뢰할 수 없는 서비스를 제공하므로 하나 이상의 조각이 도착하지 못할 수 있기 때문에 목적지 호스트가 원본 데이터그램의 마지막 조각을 수신했음을 확신하기 위해서 마지막 데이터그램 조각의 플래그 비트는 0으로, 다른 모든 조각의 플래그 비트는 1로 설정합니다. 오프셋 필드는 조각이 분실되었는지 결정하기 위해, 또 적절한 순서로 조각을 재결합하기 위해 원본 데이터그램 내에 조각의 위치를 명시합니다.
여기까지 설명한 내용을 예시로 볼까요?
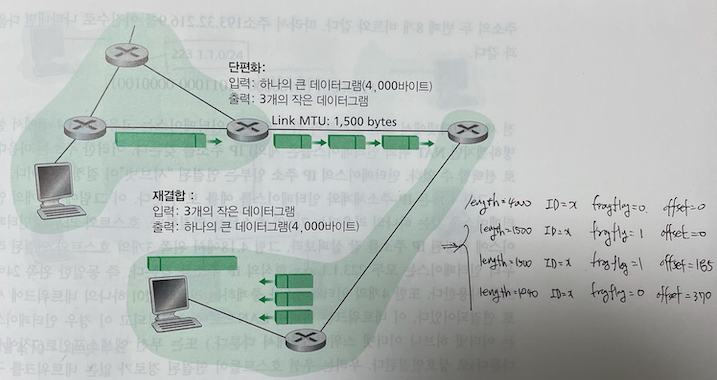
위 그림에서 출력 링크 라우터의 MTU가 1,500 바이트인데, 하나의 큰 데이터그램은 4,000바이트(IP 헤더 20바이트와 IP 페이로드 3,980바이트)입니다. 그러면 3,980바이트짜리 원본 데이터그램을 세 개의 조각으로 쪼개는 단편화가 필요하겠죠?
이 때, 각 단편화된 데이터 조각의 길이와 정보는 펜으로 써넣은 것과 같습니다.
- 1번 조각: 길이 = 1500, Id = x, flag = 1, offset = 0
- 2번 조각: 길이 = 1500, Id = x, flag = 1, offset = 185
- 3번 조각: 길이 = 1040, Id = x, flag = 0, offset = 370
여기서 조심해야 하는 부분은 쪼개는 데이터그램도 IP데이터그램의 포맷을 맞춰야 한다는 것입니다. 따라서 헤더크기인 20바이트를 고려해서 3980바이트를 1480 + 1480 + 1020의 페이로드 크기로 나누고, 각각에 20바이트의 헤더를 더해서 1500, 1500, 1040이 되는 겁니다. 그리고 Offset은 첫번째 단편의 페이로드 나누기 8(바이트)로해서 나온 값으로 설정하기 때문에 2번 조각의 경우 1480 / 8 = 185가 됩니다.
목적지 호스트는 세 번째 조각의 플래그 비트가 0인 것을 보면, 이게 마지막 조각이라는 것을 알 수 있고, 만약 어떤 조각이 도착하지 않았다면 갑자기 껑충 뛴 오프셋 필드를 관찰하면 되는 것입니다.
이렇게 이번 포스팅에서는 IPv4 데이터그램의 포맷과 데이터그램 단편화에 대해 공부했습니다. 모든 내용이 꽤 중요하고 나중에 다시 인용될 것 같으니 잘 이해해야 할 것 같습니다.
감사합니다.
'CS > Network' 카테고리의 다른 글
| [네트워크/Network] 비연결형 트랜스포트 UDP 정리 (0) | 2021.10.15 |
|---|---|
| [네트워크/Network] IPv4 주소 체계와 DHCP (0) | 2021.10.13 |
| [네트워크/Network] 라우터의 패킷 지연과 패킷 스케줄링 방법 (0) | 2021.10.11 |
| [네트워크/Network] HTTP 스트리밍 및 대시(DASH) 기술 (0) | 2021.10.10 |
| [네트워크/Network] 라우터의 입력 포트 처리 및 목적지 기반 전달 (0) | 2021.10.09 |





